AREX Community Edition
The Community Edition follows the Apache 2.0 license for open-source access to source code, offering a real automated API testing with real data.
Introduction
Background
For newly launched simple services, testing can be accomplished through a combination of automated and manual testing. However, for complex online business systems that undergo frequent updates, it is crucial to ensure the accuracy of core business functions during modifications.
Traditional automation testing often requires significant human resources for test data preparation and script creation, and may not provide adequate coverage. To maintain the stability of online systems, both developers and testers face the following challenges:
- After development, it can be challenging to quickly verify locally and identify initial issues.
- Preparing test data, writing and maintaining automation scripts are time-consuming and may not provide adequate coverage.
- It is difficult to verify the data written to services, and testing may produce dirty data, such as in our core trading system, which may write data to databases, message queues, Redis, etc. This data is often difficult to verify, and the data generated by testing is also difficult to clean up.
- Online issues are difficult to reproduce locally, making it difficult to debug.
What is AREX?
AREX solves the challenges of automated testing by replicating real online traffic to the test environment for automated API testing.
AREX captures request parameters, return results, and some snapshot data during execution, such as database access parameters and results, as well as parameters and results for accessing remote servers, using AOP. It then sends the snapshot data to the test machine (the machine where code changes occur) to complete a replay process. By comparing the stored data, the data from calling backend requests, and the return results with the data from actual online requests, differences are identified to detect issues within the tested system.
AREX can record all operations of the application's underlying dependencies on external systems, including database operations and requests to external systems. During replay testing, when related methods are triggered, AREX extracts information from the recorded data and returns it directly to the application, avoiding interactions with the actual database or other dependencies, reducing reliance on specific environmental data, and focusing on validating the program's logic and functionality.
AREX also supports testing of write interfaces perfectly. For example, in critical scenarios such as order storage and calling third-party payment interfaces, the core mechanism of AREX traffic replay is to intercept and mock framework calls, using recorded data to replace actual data requests, ensuring that no real external interactions, such as database write operations or third-party service calls, occur during the testing process, effectively preventing the writing of dirty data during replay testing.
The API testing supported by AREX includes:
- Regular testing, similar to Postman interface testing, including test setup, execution, and result assertion (ASSERT)
- Replay testing, using actual production data for replay testing and comparing the differences in return results
AREX Components
AREX consists of multiple modules including the AREX Java Agent, UI (frontend service), Schedule Service, Storage Service, API Service and data storage modules like MongoDB and Redis.
| ID | Instance | Model Name | Description |
|---|---|---|---|
| 1 | n | AREX Java Agent | A lightweight Java Agent used for traffic capture and replay. |
| 2 | 1 | Schedule Service | Sends replay requests and retrieves all responses for comparison. |
| 3 | 1 | AREX-API | Provides all API interfaces for the AREX frontend page. |
| 4 | 1 | Storage Service | Provides the function to save recordings and retrieve responses in a Mock manner for AREX Agent. |
| 5 | 1 | AREX-UI | The frontend page for AREX. |
| 6 | 1 | MongoDB | Database for data storage and configuration management. |
| 7 | 1 | Redis | High-speed replay cache. |
Workflow
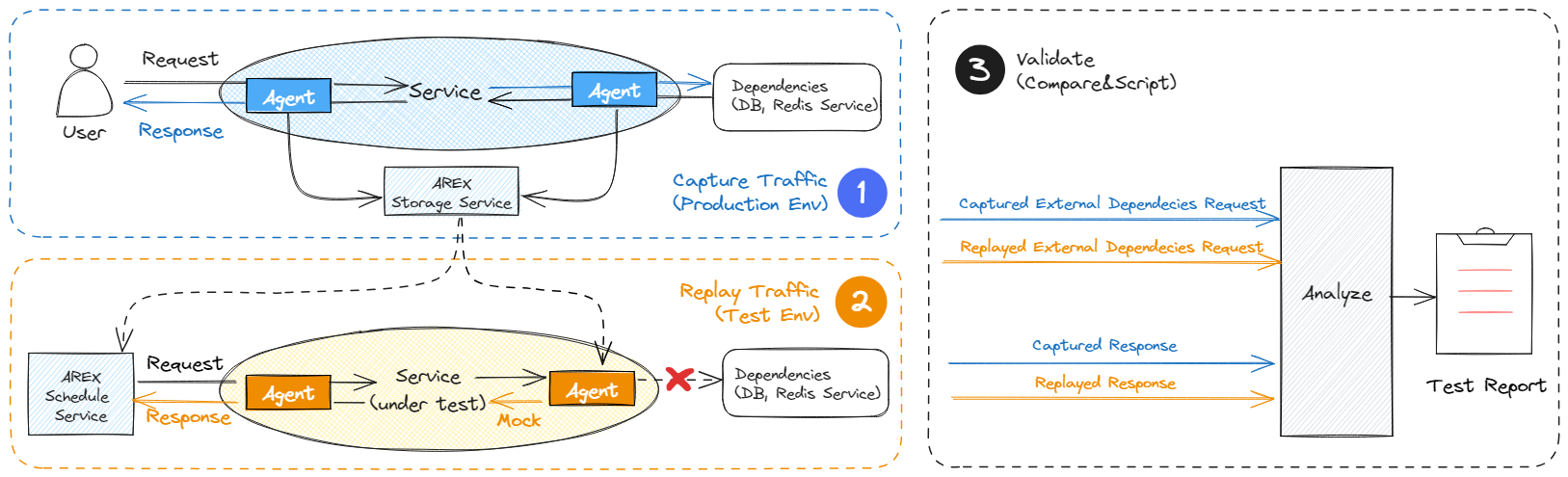
1. Traffic Capture:
- The AREX Java Agent, attached to Java applications in the production environment, records both inbound traffic to your API and outbound traffic to its dependencies, including the resulting responses.
- Recorded data is forwarded to AREX Storage Service for storage in a MongoDB database.
2. Traffic Replay:
- The Schedule Service replays the recorded application traffic back to the same application in the test environment, simulating production environment behavior.
- The application in the test environment is also attached with the AREX Java Agent. When the application try to call to any dependencies like DBs, other services, AREX Agent will intercept and provide the previously recorded dependency response.
3. Result Verification and Reporting:
- AREX compares API responses and outbound traffic to dependencies, like databases or external services, with previously recorded traffic, and then generates a report.
Core Advantages
✅ High Coverage Without Writing Tests
- No code intrusion, minimal integration cost
- No need to write test cases, a massive amount of online requests ensures high coverage
✅ Automate Testing with Mocks, No Need to Setup Test-environment
- During replay, application avoids actual calls to the database and other downstream components by mocking dependencies. It utilizes previously captured requests and responses, eliminating the need to maintain active dependencies for testing.
- Supports test WRITE calls, including validation of database, message queue, Redis data, and even runtime memory data without generating dirty data during testing. Replace external dependencies with mock data.
- Supports automatic data collection and mocking for various mainstream technology frameworks, and supports local time, caching, and accurately reproduces the production data environment during replay.
✅ Secure and Stable
- In terms of data security, it offers comprehensive permission control and traffic desensitization mechanisms.
- Code isolation is implemented along with health management, and during system busy times, it intelligently reduces or stops data collection frequency, not affecting online applications.
✅ Lower test noise
- Strategies to manage noise involve executing tests repeatedly to detect inconsistent fields and employing methods such as time mocking to prevent session token expiration.