
This post is organized from the keynote speech of MTSC 2023 Shanghai. Speaker: Wang Haibing, R&D Energy Efficiency Team Manager and SRE @Ctrip Flights BU.
Background
With the increasing scale of Ctrip's Flights BU business, the business system is becoming more and more complex, and various problems and challenges come along with it. For the R&D test team, it faces various performance dilemmas, including high business complexity, heavy workload of data construction, full regression testing, high communication cost, large number of test cases and difficult to reuse, high maintenance of test data, and automated use case management. Each of them affects the efficiency and quality of the testing team and brings challenges to the software development process.
To summarize, there are two core difficulties: cost and complexity.
- On the cost side, we usually need to make a trade-off between cost and quality. We need to ensure quality while iterating quickly, and need to ensure quality with limited cost.
- In terms of complexity, when business rules are accumulated for a period of time, the complexity of business processes, rules, scenarios, and data processing increases quadratically or exponentially after superposition, which brings great challenges to test quality.
Exploration and Practice of Automated Regression Testing
To address these challenges, we have undertaken some ongoing exploration in our quality and testing work:

- AUTO test platform: conventional programmable use case design management and execution platform. 2.
- Record and Replay Test: Introducing TCP Replay for replay test. It can simplify the test design, but there is no expected test results, and human resources are needed to pay attention to analyzing the results.
- Test Data Construction: Generate data through scripting combined with interface access to solve the problem of daily data dependency, but the labor cost of construction is very high, and it needs continuous investment.
- data MOCK platform: build multiple MOCK platforms for different scenarios to solve the test data problem. 5. various coverage platforms: build multiple MOCK platforms for different scenarios to solve the test data problem.
- Various types of coverage platforms: measure the scope of testing and workload.
- Optimized test environment: build benchmark test environments and sub-environments to ensure the needs of continuous tuning and testing.
In addition to this, there are many other attempts at testing frameworks, SQL log analysis, unit test case generation, Chaos failure rehearsal platform, and so on.
Problems encountered in exploration
All the above explorations have made some effect, but there are still two problems.
- Automated testing focuses on automated execution, and the maintenance work is still "manual", and the output ratio is not very optimistic.
- In the scenarios that need to construct a large amount of test data, large scope regression testing, and frequent release scenarios, regardless of manual testing or automated testing, the development and testing are still faced with a huge workload, including the maintenance of use cases and data, the pain points of the test has not been effectively resolved.
New construction targets
Therefore, the R&D team gave us a new construction goal:"Quality should be improved and guaranteed. It's fine to cost electricity, but not people."

Based on all the above exploratory experiences and new goals, the idea of "regression testing with real production traffic and data" was realized. Eventually, we transformed this idea into concrete thoughts and put it on the ground by building AREX, an automated testing platform that combines recording + replay + comparison, which is now open-sourced(https://github.com/arextest).
- Record: not only record the request in production environment, but also record the data involved in the request processing.
- Replay: not only playback the request, but also MOCK the data involved into the application.
- Comparison: Replacing test assertions with a comparison of the differences between the recorded and played back requests.
AREX Platform Introduction
What is AREX?
AREX contains a Java Agent and service components such as UI, storage, scheduling, reporting, database, etc. The overall architecture is shown in the figure below.
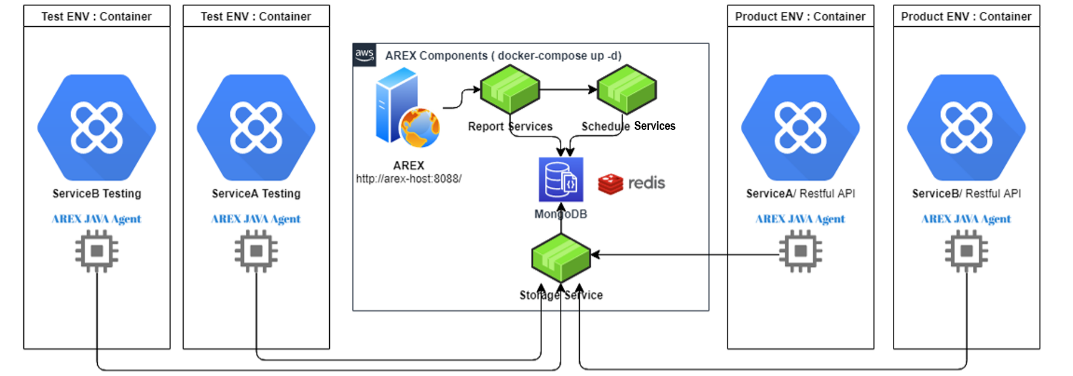
AREX Regression Testing Logic
The implementation logic of AREX regression testing is to perform comprehensive and fast regression testing of new versions of applications by recording near-full-volume business scenario requests and data in the production environment, and then replaying these real requests and data in the test environment.
Target Scenarios
- Testing scenarios that require frequent and large amounts of data creation
- Scenarios that require regression testing for a large number of businesses
- Development scenarios with a lack of testing human resources
- Frequent release, frequent regression testing scenarios
Let's explain how AREX works from a workflow perspective.
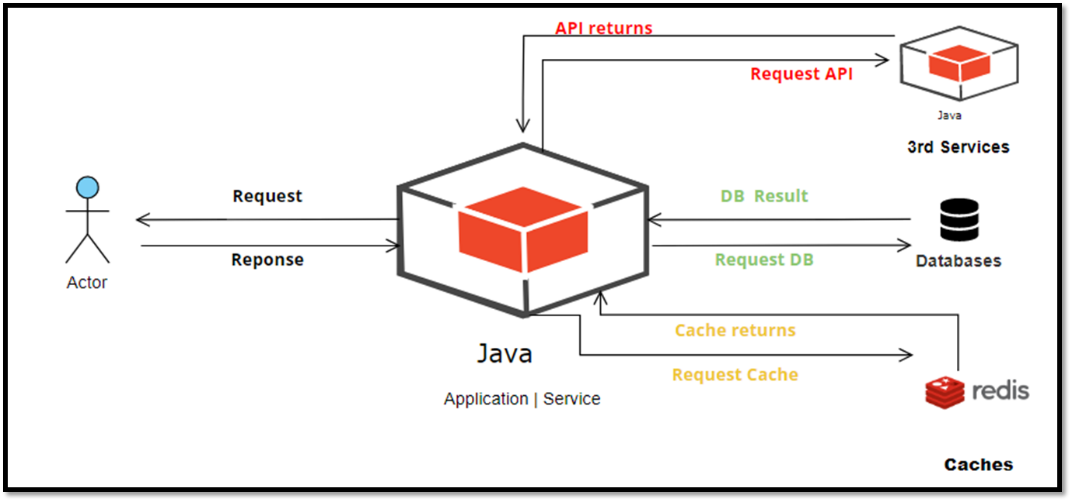
The following figure shows the call chain for an application without AREX.
When AREX is injected, as shown below, the above is the traffic recording process. In the normal call processing flow, the AREX Java Agent intercepts the data on the call link and saves it to the AREX database.
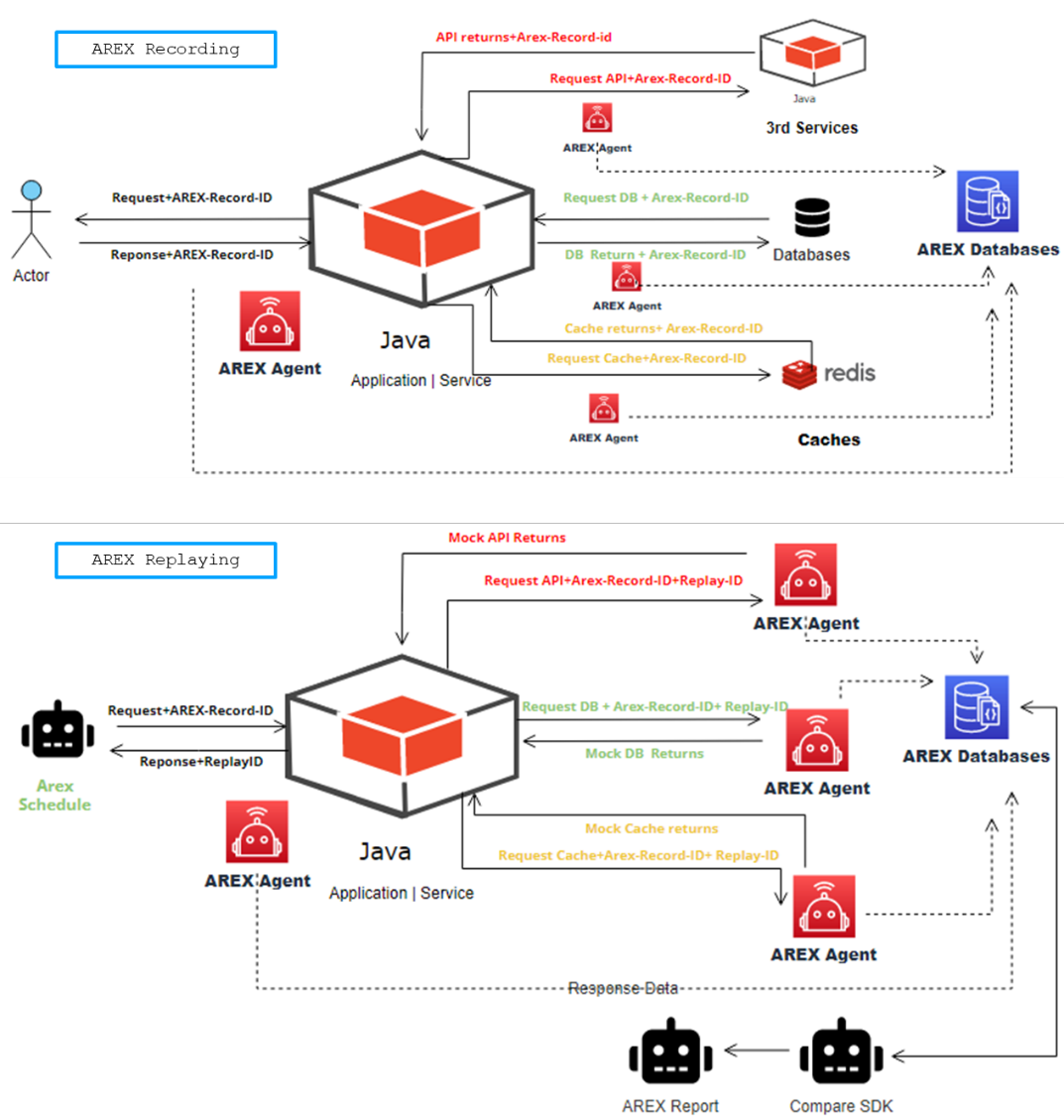
Below is the replay process, where the third-party dependencies are not actually accessed during the replay request, and AREX truncates the call chain, with the Agent reading the previously collected data from the database and returning it to the caller.
After the AREX replay test cases are executed, the comparison SDK is called by AREX to perform the comparison, output the differences, and generate a test report.
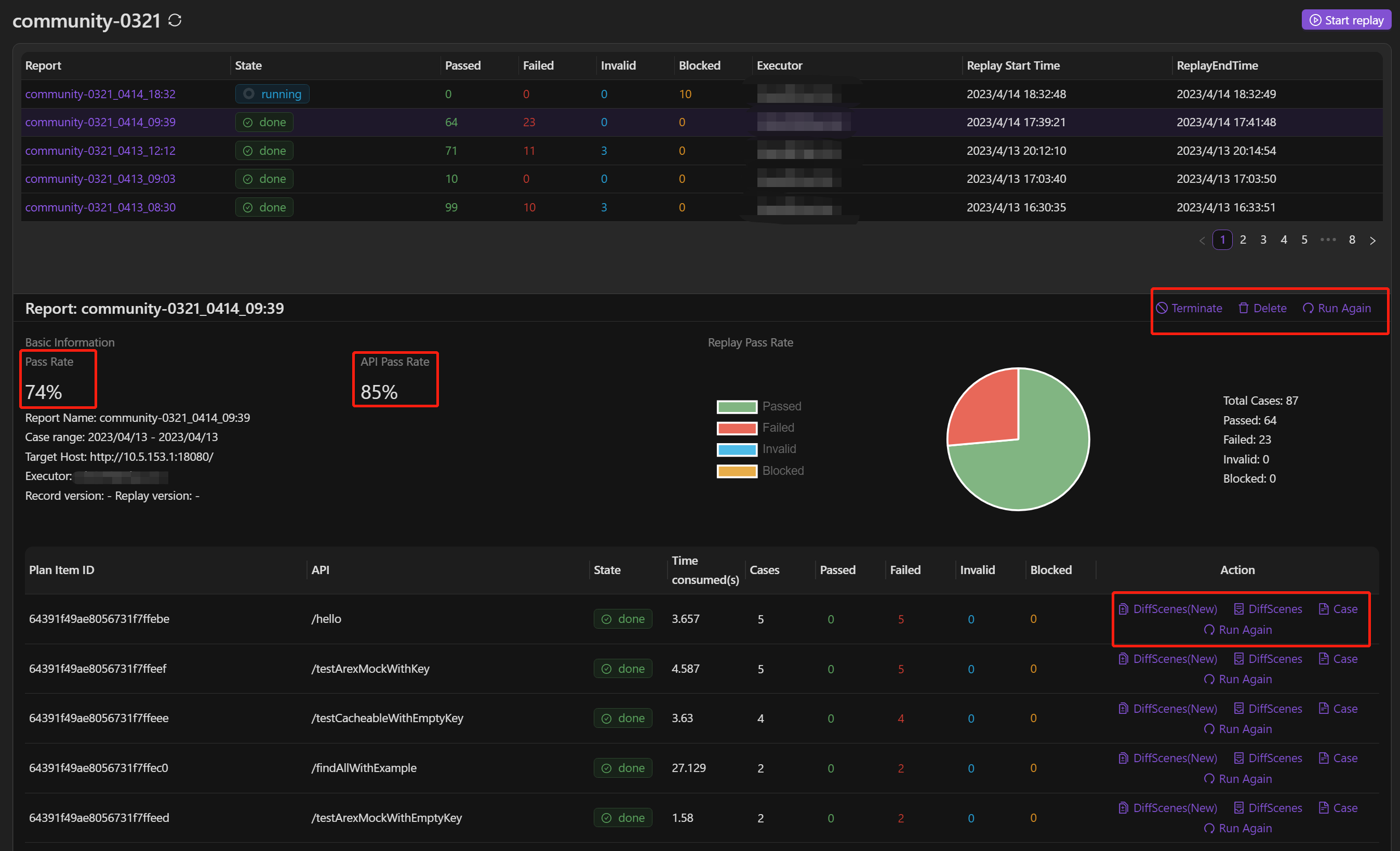
Technology implementation and optimization
Although the technology of traffic recording and playback has been developed for a long time, it is not so easy to implement, and there are many difficulties to be solved. Below is a detailed description of the technical difficulties our team encountered when implementing the AREX platform and how we solved them.
Principle of recording and replay
The following is a simple function to illustrate the recording and replay principle of AREX Agent:
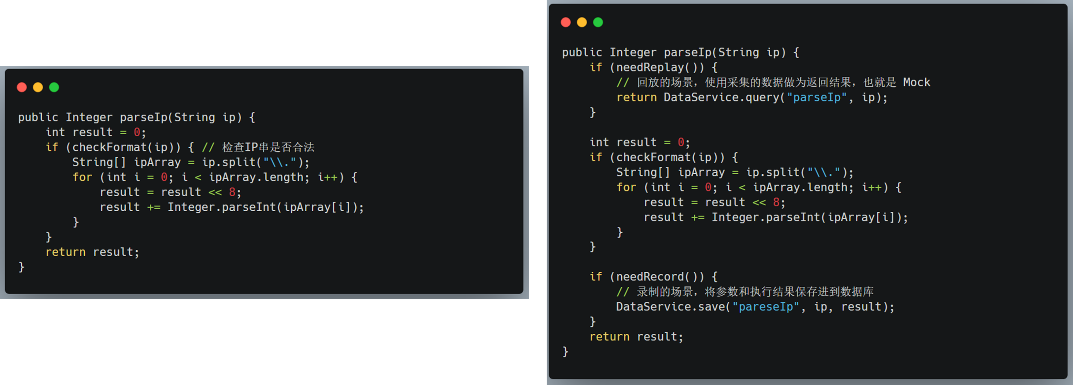
The left side is the function before conversion and the right side is the function after conversion.
In the entry part of the function, a playback judgment is made. If playback is required, the collected data is used as the return result, i.e., Mock.
In the exit part of the function, a recording judgment is made. If recording is required, the intermediate data that the application needs to save is saved to the AREX database.
The principle of dependency package injection is as simple as this.
The technical challenge
AREX AGENT Technology Stack
We used the ByteBuddy to implement bytecode modification due to good performance and easier to read and understand code.
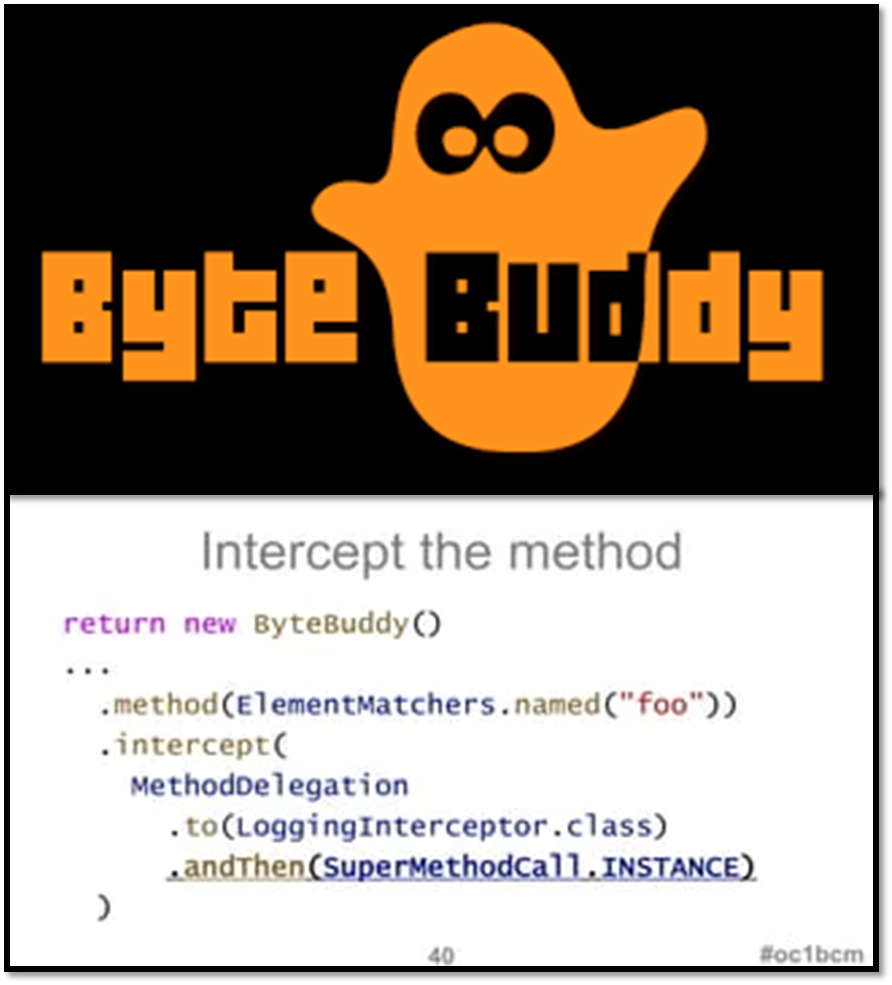
We also used the Service Provider Interface, a set of APIs provided by Java for doing extensions, which can be used to enable framework extensions and replacement components. Our injected components are realized through this plugin pattern.
Achieve TRACING
The recoding functionality of AREX requires that requests, responses, and third-party requests and responses be recorded, and that these data be linked together with a unique key that can be used as a complete test case, which is AREX's Record ID.
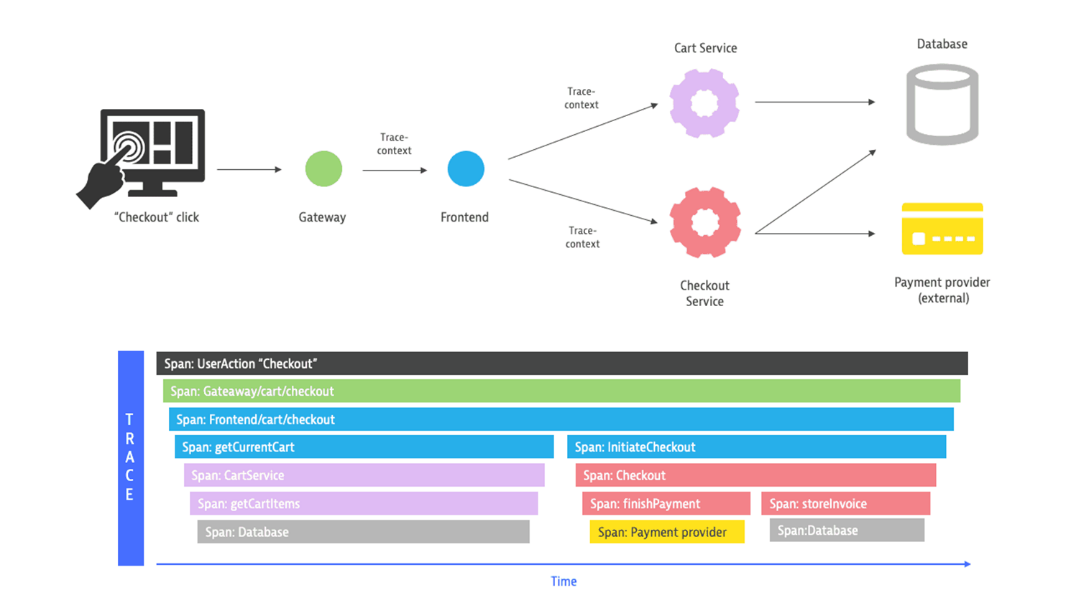
The following classes implement the AREX call chain. At the beginning of the call chain, the Agent generates a unique Record ID and saves it in a Thread Local variable. Agent code is injected into the function header and tail of the application, and this code reads the value in the Thread Local variable and stores it with the intercepted data.
Resolving Lost Call Chains
The above are the most common scenarios in AREX TRACING delivery implementations. In addition to this, there are a lot of scenarios in our applications that use multi-threading, asynchronous and other techniques, in which the call chain will be lost, making it very difficult to string data together.
In order to solve the problem of missing call chains, we implement wrappers for the classes Runnable, Callable, ForkJoinTask, Async Client.

The basic principle is to replace the original code with our wrapper class where the multi-threaded code is called, while retaining the original functionality in the wrapper class, and at the same time realizing the data reading and writing functions of AREX.
Tip: Wrapper is a keyword, search for Wrapper in the code base to see all AREX wrapper class implementations.
Enables recording and playback injection
Below is an example of code that implements recording playback.
@Override
public List<MethodInstrumentation> methodAdvices() {
ElementMatcher<MethodDescription> matcher = named("doFilter")
.and(takesArgument(0, named("javax.servlet.ServletRequest")))
.and(takesArgument(1, named("javax.servlet.ServletResponse")));
return Collections.singletonList(new MethodInstrumentation(matcher, FilterAdvice.class.getName()));
}
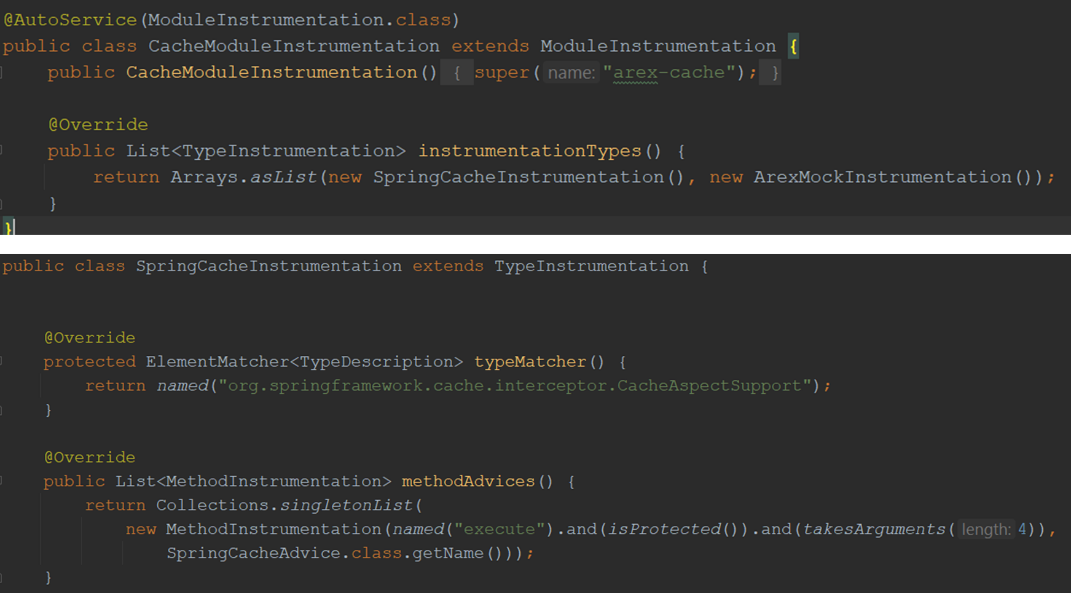
When we need to implement the injection of a new dependency library, how do we implement this plugin?
First, we locate the injected function by three elements:
- Module (ModuleInstrumentation: FilterModuleInstrumentationV3): logical management of the concept of multiple injected classes, or wrapper classes, into a module.
- type (TypeInstrumentation: FilterInstrumentationV3): that is, we want to locate the injection object class, that is, the application class being injected.
- function (MethodInstrumentation): this function to locate the function to be modified by the injection.
As in the above example, the class we want to inject is the CacheAspectSupport class, the module is the CacheModuleInstrumentation module, and the function we want to inject the modification is the doFilter function.
The next step is to implement the function injection code in three steps. Below is a Mybatis Query() function to visualize how AREX Agent implements code injection:
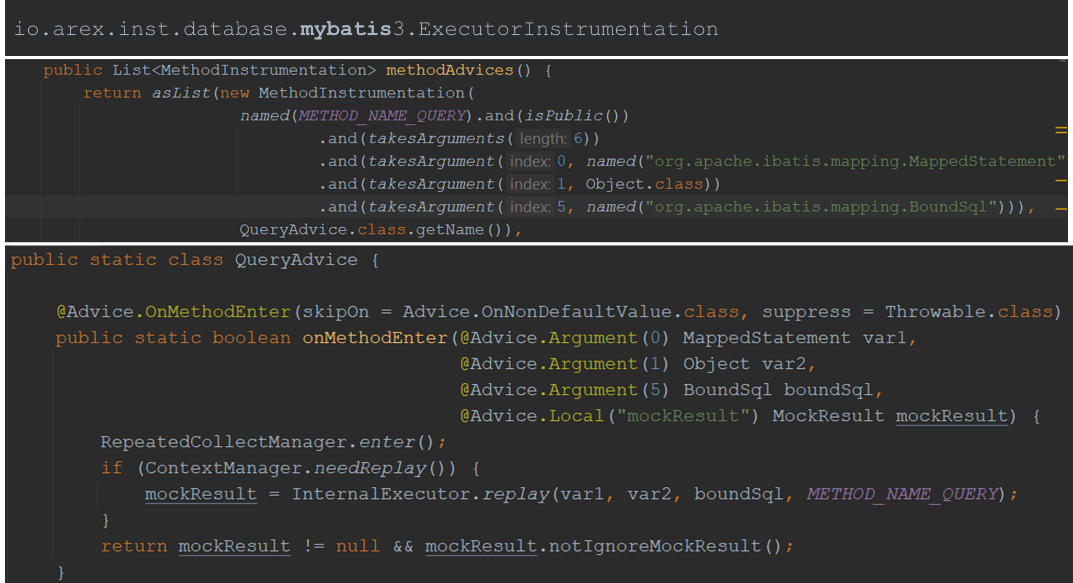
Step 1: Associate the function named METHOD_NAME_Query (string "Query") with the class QueryAdvice, which is the class that implements the injection functionality.
Step 2: The QueryAdvice class implements the function OnMethodEnter() and is labeled with ByteBuddy's Annotation.
Step 3: The QueryAdvice class is injected into the header and tail of the Query function.
If playback is required, the queried data is stored in a local variable; if playback is not required, execution continues.
The following is the injected code for the Query function before it exits:
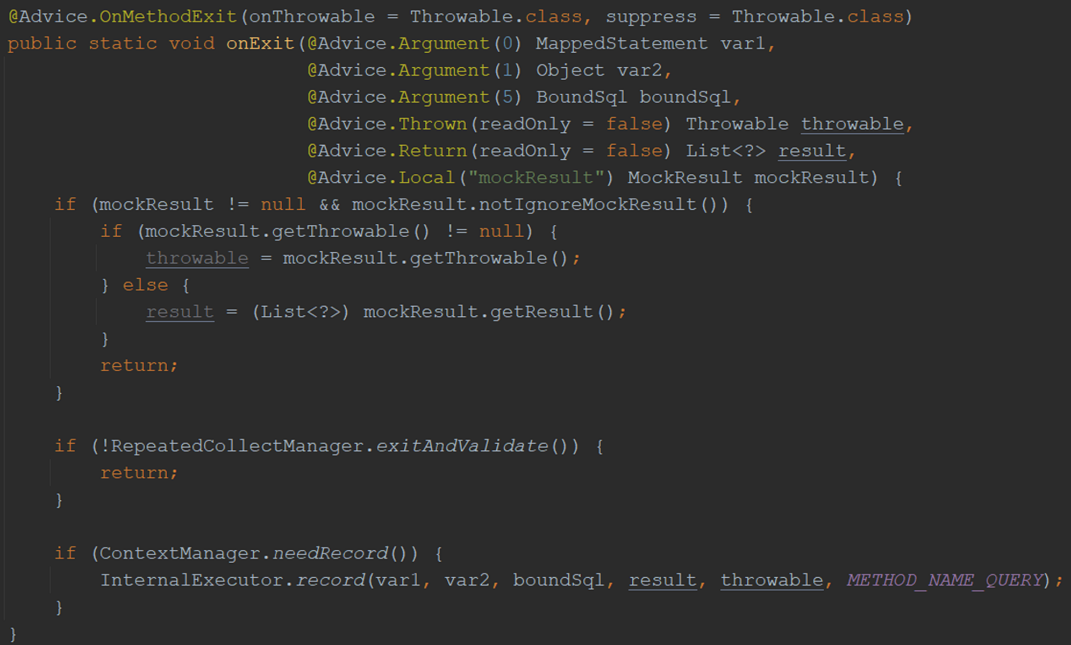
- If the MOCK result matches the condition, the MOCK data is returned;
- If the current status is recording, the query SQL + query result raw data is saved to the database of AREX.
Implementing Version Management
Popular components often have multiple versions that are used on different systems at the same time, and the implementations of the different versions may be very different or even incompatible.
To address this problem, AREX makes multiple versions compatible. In the application startup, AREX Agent will capture all the dependent package information, such as JAR package Manifest.MF file, from the Manifest to get the version information of the library, and then according to the version information to start the corresponding AREX injection code, thus realizing the realization of multiple versions of compatibility.
As shown in the following figure, the version range of the current injection script adaptation is set so that AREX can identify the versions of the components that the application depends on before these classes are loaded, and then later match the versions when the classes are loaded to ensure correct code injection.

Implementing Code Isolation
Since most of the scenarios in which AREX is used are recording in the production environment and playback in the test environment, stability is of paramount importance. For the stability of the system and to prevent the Agent's code from affecting the code execution of the application under test, AREX has realized code isolation and interoperability.
The AREX core JAR is loaded in an independent ClassLoader, which is not interoperable with the user's application code. In order to ensure that the injected code can be accessed correctly at runtime, a simple modification to the ClassLoader is made, as shown in the following figure.

Time Mock
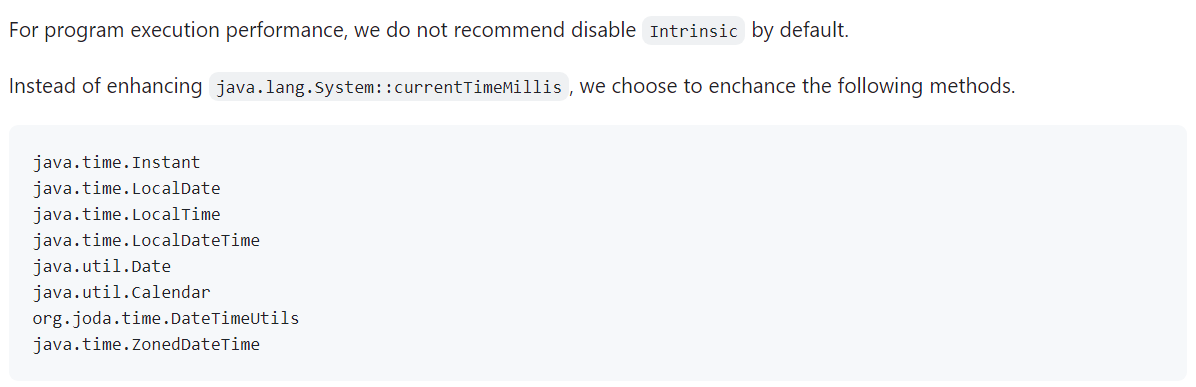
Many business scenarios in Ctrip are time-sensitive, and we often encounter situations where the recorded time has expired during playback, and the business logic can't go on, resulting in playback failure.
We use our own implementation of currentTimeMillis() to proxy Java's original currentTimeMillis() call, the time recording and playback will be executed according to the scene at the time of recording, so as to realize the time mock.
This scenario is described in detail in AREX Agent #182:
Cache Mock
Applications in real production environments always use various types of caches to improve runtime performance, due to the differences in the cached data caused by the inconsistent execution results, in the recording of playback is a big problem.
AREX provides a dynamic class Mock function, the implementation method is to access the local cache method configured as a dynamic class, equivalent to your customization of the method for Mock, will be recorded in the production environment you configure the dynamic class method data, replay corresponding to the match out of the data returned.
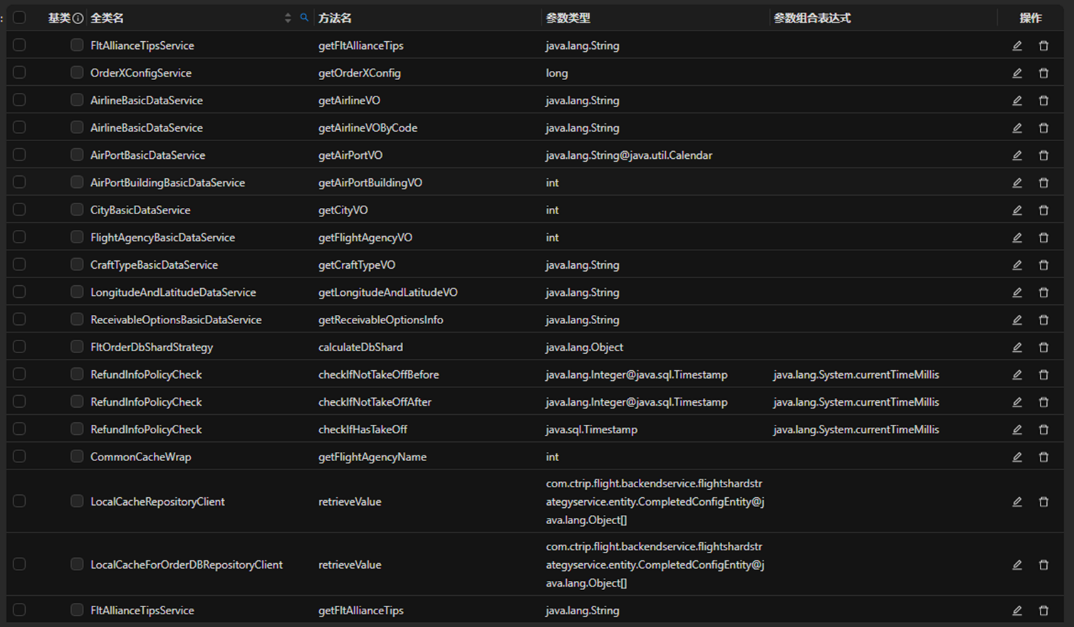
Of course there are shortcomings in this approach:
- Cache configuration is easy to ignore, which has a great impact on the replay pass rate;
- Each application has its own cache implementation, which cannot be processed in advance and requires manual involvement with configuration costs.
Other Advantages
Support for validating data written to the database
To verify the correctness of the modified business of the system, it is not enough to only verify the return results, usually it is also necessary to verify the correctness of the intermediate process data, such as the business system to write the correct content of the database data, and so on.
AREX records the database requests to the outside world of both the old and new versions of the system during recording and playback, and compares the two requests, showing the differences in the playback report if any.
Since AREX mocks all third-party dependent requests, supports validation of database, message queue, Redis data, and even runtime memory data, and doesn't actually make calls to the database during playback, it doesn't generate dirty data.
Troubleshooting Production Problems
AREX can also be used to quickly locate production problems.
After a production problem occurs, it is difficult for developers to reproduce the problem locally due to version differences, data differences, etc. Debugging is very costly and laborious.
With AREX, you can force the production environment to record the problematic cases (a unique Record ID will be generated in the answer message), then start the local development environment, add this Record ID to the header of the request message, then you can locally recover the recorded request and data, and then use the local code to directly debug the production problem.
Implementation and Outlook
AREX in Ctrip
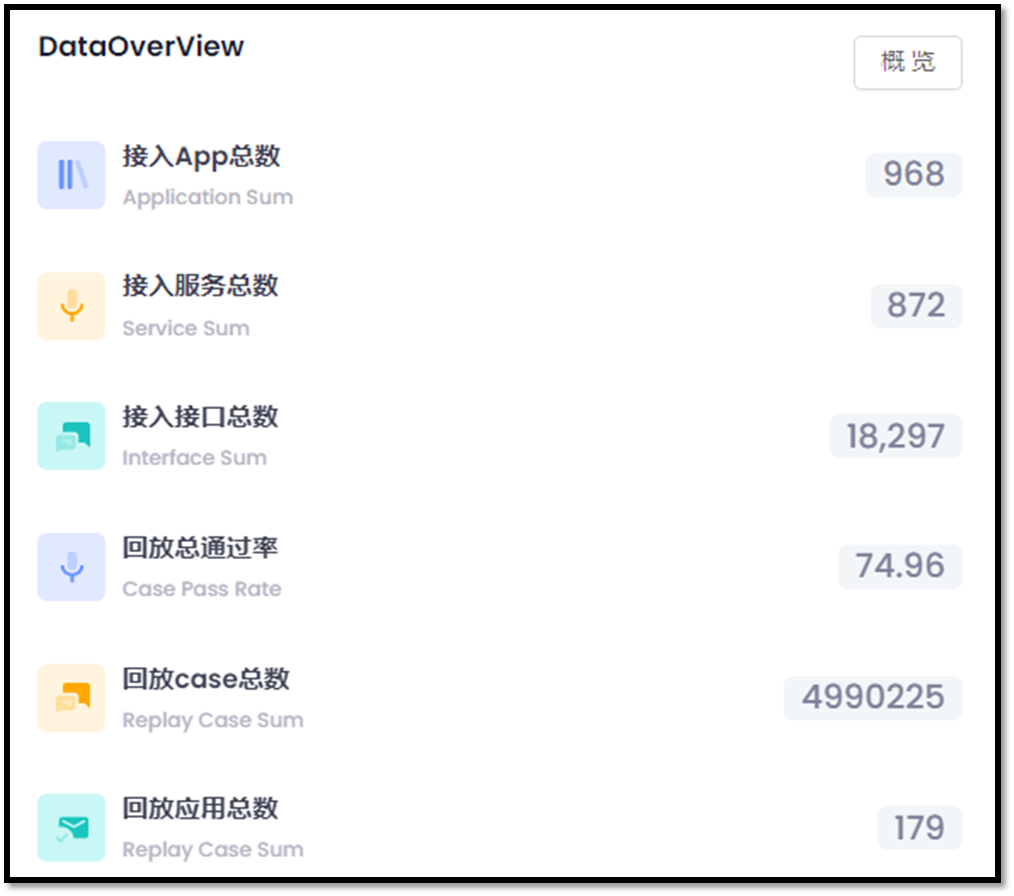
After BUs accessed AREX, in addition to the learning cost of familiarizing themselves with the tools and configurations in the early stage, the workload of test developers in automation use case development, data MOCK, and constructing data was obviously reduced, forming a virtuous cycle, reducing leakage of tests and increasing the coverage, and effectively improving the quality of products.
The effect is most significant in two scenes:
- Technical refactoring projects, especially in scenarios where requests are answered without modification. In this scenario, there is almost no need for testers to participate, and the developers themselves can quickly conduct self-tests through AREX to ensure quality.
- Developers to improve the quality of self-testing.
AREX Optimisation
Initially, AREX was used on a small scale at Ctrip, and was well received. However, problems arose when expanding its use, especially when there was unsolicited access by other teams:
- High false positives (time, uuid, serial number, etc.), lots of pre-comparison filtering configurations.
- Expected confirmation of code changes is cumbersome, with a high amount of manual intervention.
We are currently focusing on optimizing the AREX configuration and comparison capabilities.
Configuration Enhancements
At this stage, to ensure a high comparison pass rate requires a lot of manual intervention (comparison ignores configuration, etc.), so the first thing to do is to reduce the cost of configuration for users:
- Visualization intuitively show the differences
- Manual labeling operations to improve ease of use
- Configuration updates can be recalculated and re-executed
Aggregation of Similar Differences
Multi-dimensional aggregation of similar differences by means of aggregation makes it easy for developers to observe the differences. Ultimately, it achieves the effect that in most cases, the developer only needs to confirm one discrepancy to remove most of the comparison discrepancies.
Algorithmic Noise Reduction
- Pre-analyze Noise Reduction
Pre-analysis noise reduction is to release the production version of the recorded traffic to the test environment, playback this version and compare its differences, and identify the "noise" points such as tokens, serial numbers, etc. in advance.
The noise is then tagged to a rule base, which serves as a knowledge base.
Finally, it identifies changes in the Schema of messages and data, and proactively reduces noise to minimize the cost of manual configuration by users.
- Comparison Knowledge Base
Comparison is the core capability of AREX, but the current comparison is relatively rough, with a high false alarm rate. We hope to increase the accumulation of comparison knowledge (without human intervention) during the iterative testing, and form a comparison knowledge base, which can help users accurately identify valid differences. For example, to convert the definition of Schema into valid comparison rules.
Precision Testing
Precision testing is designed to narrow down the scope of testing, and will be introduced in AREX, with the main purpose of clearly comparing the source of discrepancies.
We plan to correlate code changes, code execution links, and AREX playback, so that users can identify problems "observably" through the two-way traceability of code changes and discrepancy results. The first step is to identify whether the discrepancy is an expected discrepancy caused by a code update, and the second step is to proactively filter the discrepancy points to identify unanticipated problems.
After comparing the optimized processing of the discrepancy results, it can effectively reduce the R&D configuration costs and improve the accuracy of the discrepancy results, which is the real value of AREX's automated regression testing.
The End
AREX has gradually reached the goal of regression testing with real traffic and data after continuous optimization, which has reduced the cost, improved the quality, and reached the goal set at the early stage of construction.
Of course, there are still a lot of places that need to be optimized and improved, including algorithms, performance, support scope and so on, which need to be further optimized and developed. We also hope that all interested parties can join us in building the AREX open source project.