
本文整理自 MTSC 2023 中国互联网测试开发大会(上海站)主题演讲。 演讲人:携程机票事业群研发能效团队经理和 SRE 王海兵。
背景简介
随着携程机票 BU 业务规模的不断提高,业务系统日趋复杂,各种问题和挑战也随之而来。对于研发测试团队,面临着各种效能困境,包括业务复杂度高、数据构造工作量大、回归测试全量回归、沟通成本高、测试用例数量多且难以复用、测试数据维护量大以及自动化用例管理等问题。每个都会影响测试团队的效率和质量,给软件研发过程带来挑战。
总结下来就是两个核心困难点:成本与复杂度。
- 成本方面,我们通常需要在成本和质量之间做出取舍,需要在快速迭代的同时保证质量,又需要在限定的投入下保证质量。
- 复杂度方面,当业务规则积累一段时间后,业务流程、规则、场景和数据处理的复杂度在叠加后呈二次或者指数等形式增加,给测试质量工作带来很大的挑战。
探索:自动化回归测试的探索与实践
为了应对这些挑战,我们在质量和测试工作中进行了一些持续性探索:

- AUTO 测试平台:常规的可编程的用例设计管理和执行平台。
- 录制回放测试:引入 TCP Replay 进行回放测试,好处是可以简化测试设计,缺点是没有预期测试结果,需要人力去关注分析结果。
- 测试数据构造:通过脚本结合接口访问生成数据,解决日常数据依赖的问题,但是构造的人力成本很高,而且是持续性的投入维护。
- 数据 MOCK 平台:针对不同的场景建设多个 MOCK 平台,解决测试数据问题。
- 各类覆盖率平台:度量测试的范围与工作量。
- 优化测试环境:建设基准测试环境和子环境,保证连调和测试的需要。
除此以外,还有很多其他测试框架、SQL 日志分析、单元测试用例生成、Chaos 故障演练平台等等的尝试。
探索中遇到的问题
以上的各种探索都达到了一定的效果,但还是存在两个问题:
- 自动化测试侧重于自动化执行,维护工作依旧是“手工”,产出比不是很乐观。
- 在需要构造大量测试数据、写场景、回归测试范围大、发布频繁的场景下,不管是手工测试还是自动化测试,开发测试都还是面临着巨大的工作量,包括用例和数据的维护工作,测试的痛点并没有有效解决。
新的建设目标
因此,研发团队给我们提了新的建设目标:“质量要提升,要保证。费电可以,但不能费人。”

基于以上种种探索经验和新的目标,于是就有了 “用真实的生产流量和数据进行回归测试” 的实现想法。最终,我们将这个想法转化为具体的思路,并将其落地,建设了一个结合录制+回放+比对的自动化测试平台 AREX,现已开源(开源地址:https://github.com/arextest。)
- 录制:不只是录制生产的请求,也录制请求处理过程中涉及到的数据。
- 回放:不只是回放请求, 也把涉及的数据 MOCK 到应用里边。
- 比对:用录制回放的差异比对来代替测试断言。
AREX 平台介绍
什么是 AREX
AREX 包含了 Java Agent 和前端、存储、调度、报告、数据库等服务组件 ,整体架构如下图所示。
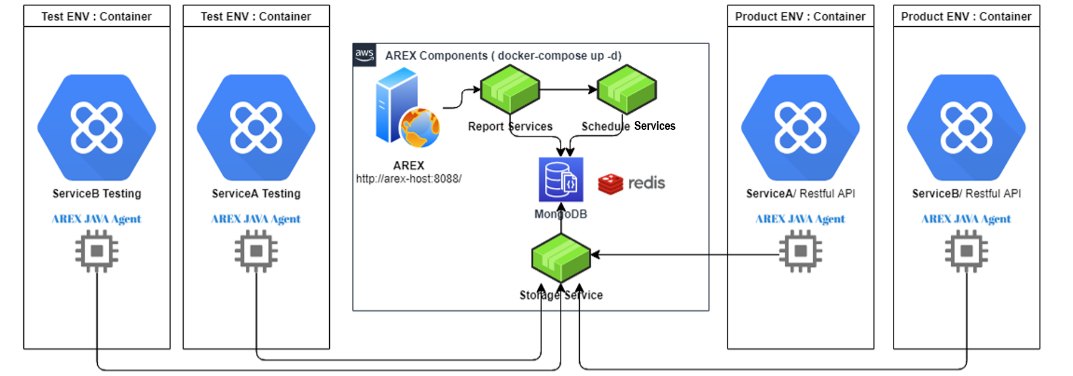
AREX 回归测试逻辑
AREX 回归测试的实现逻辑是通过在生产环境录制接近全量的业务场景请求和数据,然后在测试环境回放这些真实的请求和数据,对新版本的应用进行全面、快速的回归测试。
目标场景
- 需要频繁大量造数据的测试场景
- 需要大量业务需要回归测试的场景
- 测试人力资源欠缺的开发场景
- 频繁发布,频繁回归测试的场景
接下来从工作流程的角度,来讲解 AREX 是如何工作的。
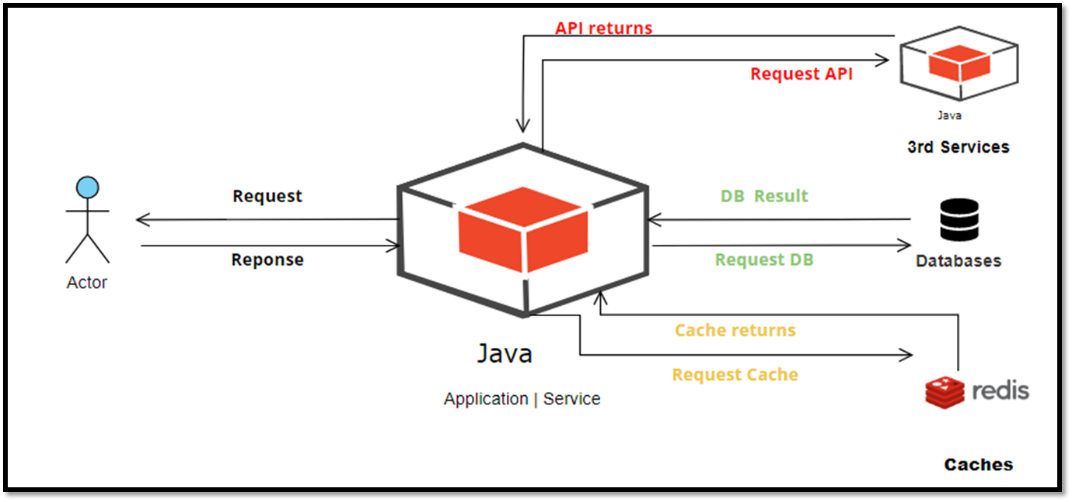
下图是没有接入 AREX 的应用的调用链。
当接入 AREX 后如下图所示,上方是流量录制过程,在正常的调用处理流程中,由 AREX Java Agent 在调用链路上截取到数据并保存到 AREX 数据库。
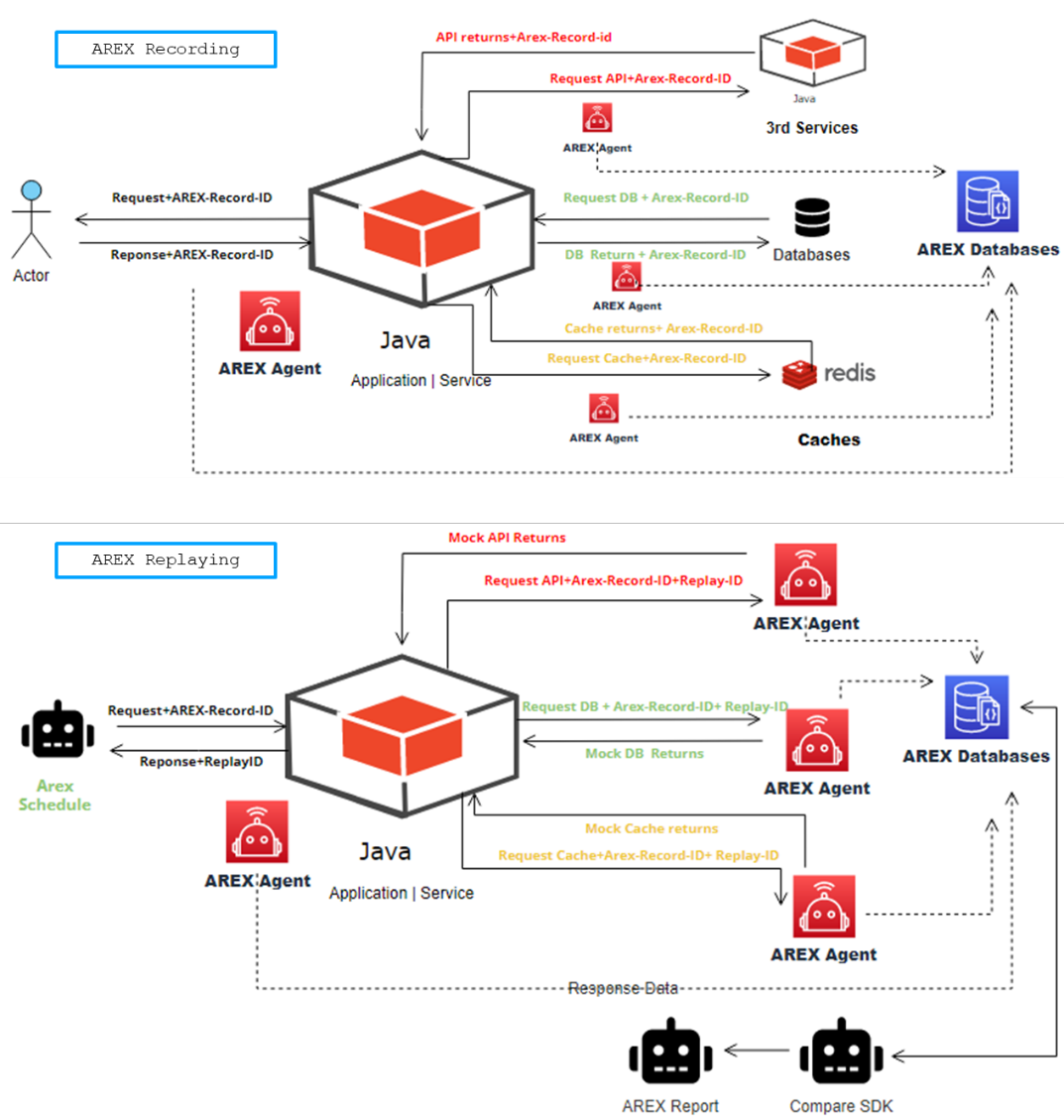
下方是回放流程,在回放请求时并不会真实地访问第三方依赖,AREX 截断了调用链,由 Agent 从数据库中读取先前采集到的数据并返回给调用方。
AREX 回放测试用例执行结束后,由 AREX 调用比对 SDK 进行比对,输出差异结果,生成测试报告。
AREX 技术实现与优化
流量录制回放的概念虽然已经是老生常谈,但是真正落地起来并没有那么容易,里面有诸多难题需要解决。下面将详细介绍我们团队在实现 AREX 平台时遇到的技术难点以及我们是如何解决这些问题的。
AREX Agent 录制回放原理
以下通过一个简单的函数,说明 AREX Agent 的录制回放原理:
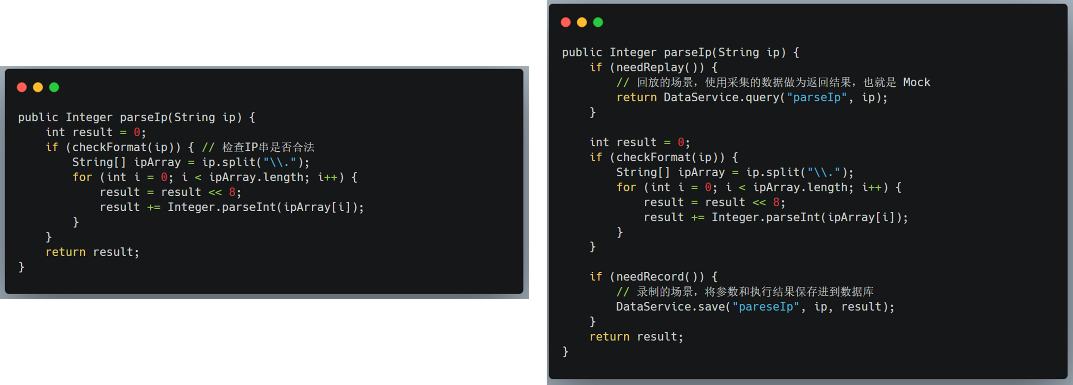
左侧是转换前的函数,右侧是转换后的函数。
在函数入口部分,做了回放判断。如果需要回放,则使⽤采集的数据做为返回结果,也就是 Mock。
函数出口部分做了录制判断,如果需要录制,则将应用需要保存的中间数据,保存到 AREX 数据库。
依赖包的注入,原理就是这么简单。
AREX 技术挑战
AREX AGENT 技术栈
由于性能好、且代码更容易阅读、容易理解,我们采用了 ByteBuddy 库实现字节码修改。
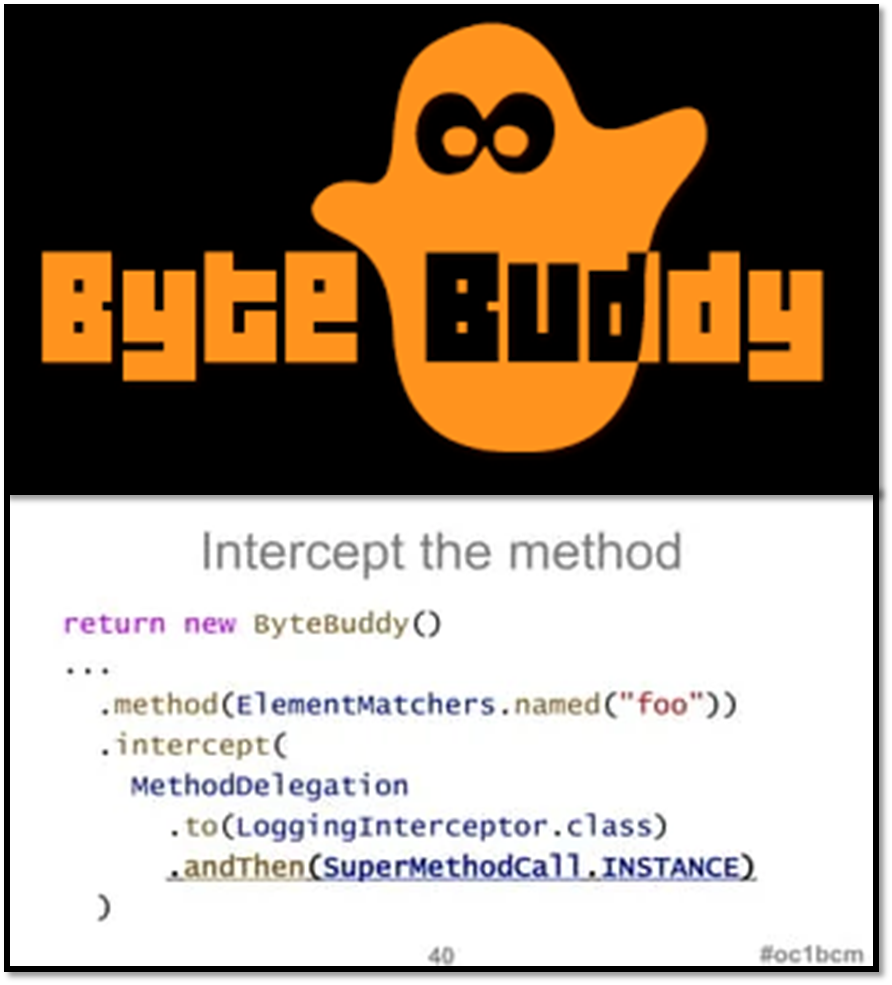
此外还使用了 SPI(Service Provider Interface),这是 Java 提供的一套用来做扩展的 API,它可以用来启用框架扩展和替换组件。 我们的注入组件就是通过这个插件模式实现的。
实现 TRACING
AREX 的录制功能需要将请求、应答、以及第三方的请求应答等都记录下来,并且需要一个唯一的 Key 将这些数据串联起来,这样才能完整地作为一个测试用例,这个 Key 就是 AREX 的 Record ID。
以下这些类实现了 AREX 的调用链路。简而言之,就是在调用链的入口处,Agent 会生成一个唯一的 Record ID 并将其保存到 Thread Local 变量中。在应用程序的函数头和尾部注入 Agent 代码,这段代码会读取 Thread Local 变量中的值,并将其与截取到的数据一起存储。
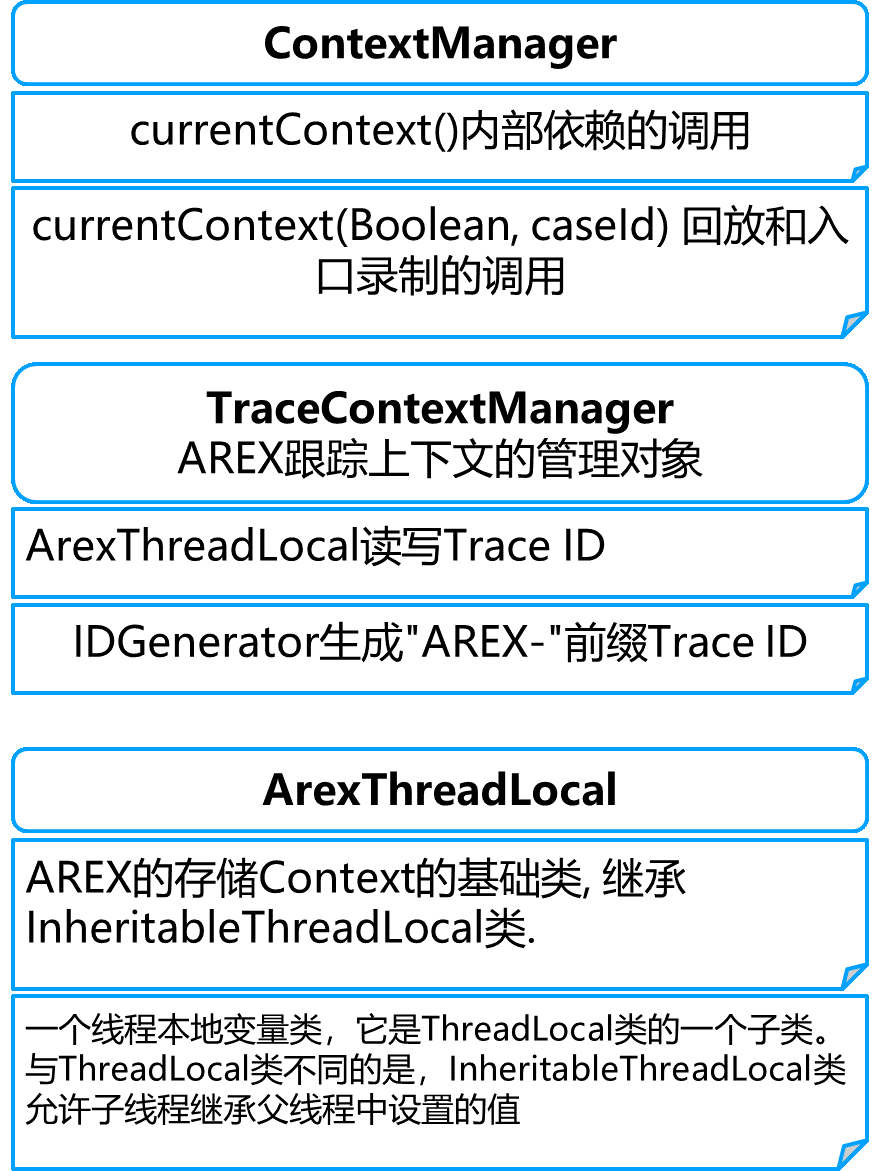
解决调用链丢失
以上是 AREX TRACING 传递实现中比较普遍的基础场景。除此以外,我们的应用中还有大量使用多线程、异步等技术的场景,这种场景下调用链会丢失,给数据的串联带来很大的困难。
为了解决调用链丢失的问题,我们实现了 Runnable,Callable,ForkJoinTask,Async Client 这些类的封装。

基本原理就是在多线程代码调用的地方,用我们封装的类替换原有的代码,而在封装类中保留原有的功能,同时实现 AREX 的数据读写功能。
小窍门:Wrapper(包装类) 是个关键词,在代码库中搜索 Wrapper 可以看到所有 AREX 封装类的实现。
实现录制和回放注入
以下是一个实现录制回放的代码实例。
@Override
public List<MethodInstrumentation> methodAdvices() {
ElementMatcher<MethodDescription> matcher = named("doFilter")
.and(takesArgument(0, named("javax.servlet.ServletRequest")))
.and(takesArgument(1, named("javax.servlet.ServletResponse")));
return Collections.singletonList(new MethodInstrumentation(matcher, FilterAdvice.class.getName()));
}
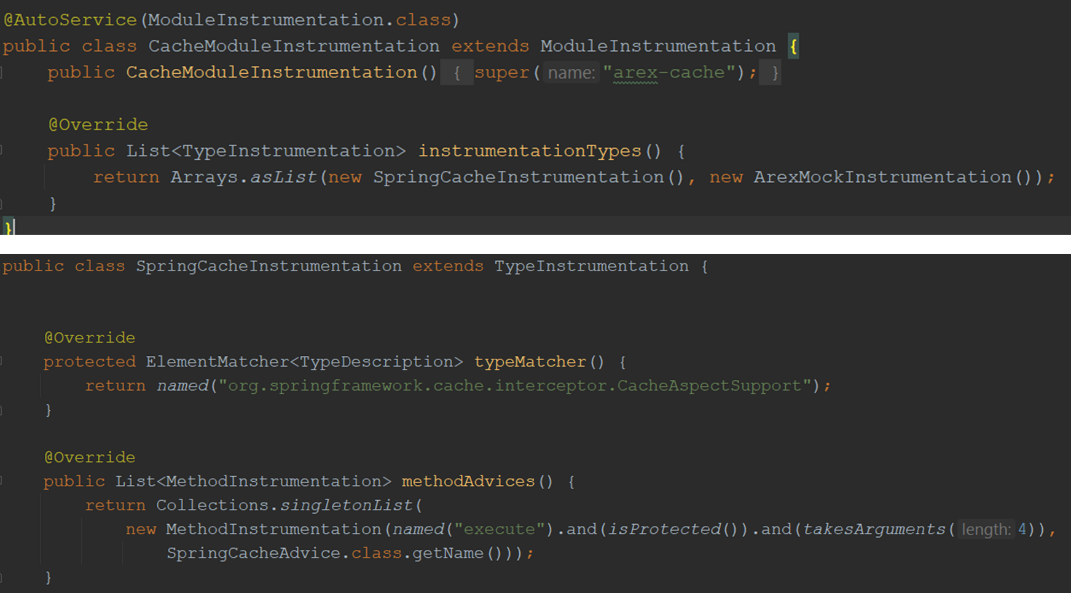
当我们需要实现一个新依赖库的注入时,是如何来实现这个插件呢?
首先,我们通过三个要素来定位到被注入的函数:
- 模块(ModuleInstrumentation: FilterModuleInstrumentationV3):逻辑管理的概念,是将多个注入类、或者封装类,放到一个模块中。
- 类型(TypeInstrumentation: FilterInstrumentationV3):就是我们要定位到注入对象的类,即被注入的应用类。
- 函数(MethodInstrumentation):此函数要定位到注入修改的函数。
如上例中,我们要注入的类是 CacheAspectSupport 类,所在的模块是 CacheModuleInstrumention 模块,要注入修改的函数是 doFilter 函数。
接下来,通过三个步骤来实现函数注入代码的功能。以下通过一个 Mybatis 的 Query() 函数来更直观地看看 AREX Agent 如何实现代码注入:
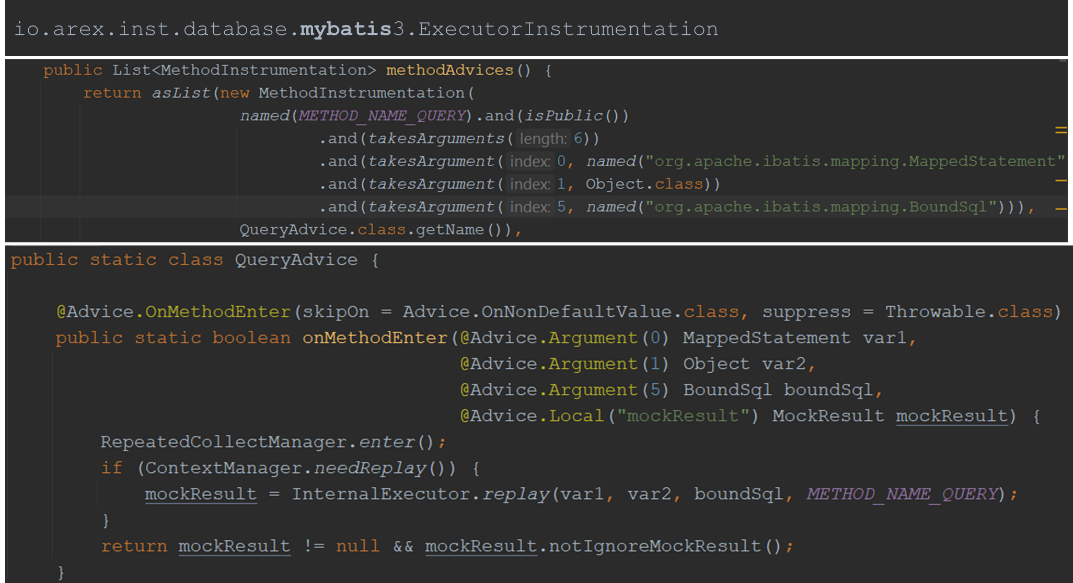
步骤一:将名为 METHOD_NAME_Query(字符串“Query”)的函数与类 QueryAdvice 关联起来,QueryAdvice 是实现注入功能的类。
步骤二:QueryAdvice 类实现了函数 OnMethodEnter(),并标注了 ByteBuddy 的 Annotation。
步骤三:QueryAdvice 类会被注入到 Query 函数的头和尾部。
如果需要回放,则将查询到的数据存储在一个本地变量中;如果不需要回放,则继续执行。
以下是 Query 函数在退出前的注入代码:
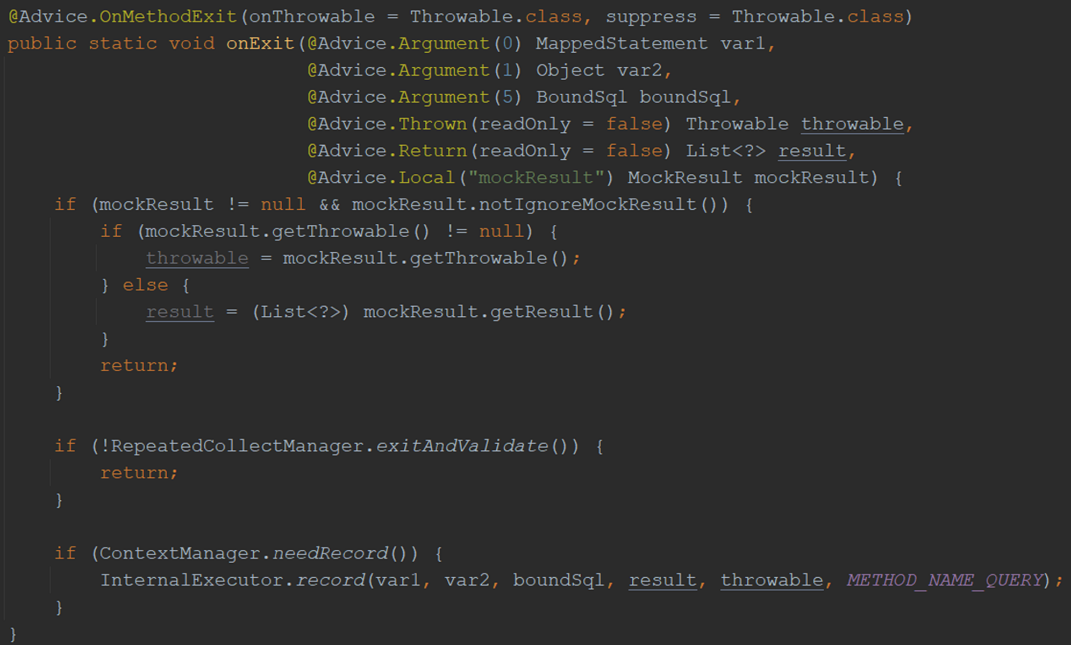
- 如果 MOCK 结果符合条件,则返回 MOCK 数据;
- 如果当前状态是录制中,则将查询 SQL + 查询结果原始数据保存到 AREX 的数据库。
实现版本管理
流行的组件往往存在多个版本同时在不同的系统中使用,不同的版本实现方式差别可能很大,甚至不兼容。
针对这种问题,AREX 做到了多个版本的兼容。在应用启动的时候,AREX Agent 会捕获到所有的依赖包的信息,比如 JAR 包的 Manifest.MF 文件,从 Manifest 中获取类库的版本信息,然后根据版本信息来启动对应的 AREX 注入代码,由此实现实现了多个版本的兼容。
如下图所示,设置了当前注入脚本适配的版本范围,这样 AREX 就可以在这些类加载前识别出应用依赖的组件版本,之后在类加载时进行版本的匹配,保证正确的代码注入。

实现代码隔离
由于 AREX 大多数的使用场景是在生产环境进行录制,在测试环境进行回放,因此稳定性至关重要。为了系统的稳定性,防止 Agent 的代码影响到被测应用的代码执行,AREX 实现了代码隔离互通。
AREX 核心 JAR 是在一个独立的 ClassLoader 中加载,和用户的应用代码不互通。为了保证注入的代码可以在运行时被正确访问,对 ClassLoader 进行了简单的修饰,如下图所示。

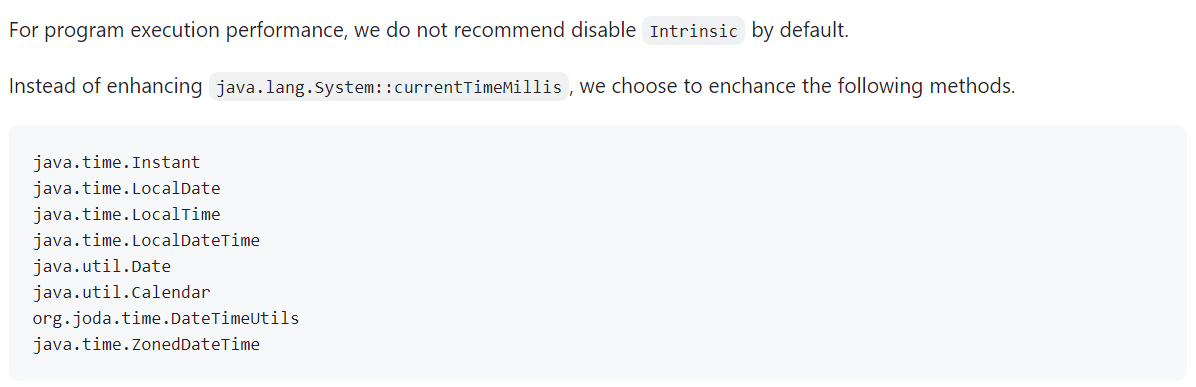
解决时间问题
携程的很多业务场景是时间敏感的,经常会遇到录制的时间在回放的时候已经过期了,业务逻辑走不下去,导致回放失败的情况。
我们用自己实现的 currentTimeMillis() 代理了 Java 原有的 currentTimeMillis() 调用,时间的记录和回放都将按照录制当时的场景来执行,从而实现了时间的 Mock。
在 AREX Agent #182 针对此场景进行了详细的描述:
解决缓存问题
实际应用中会使用各式缓存来提升运行时的性能,由于缓存数据的差异导致的执行结果不一致,在录制回放里边是一个很大的问题。
AREX 提供了动态类 Mock 的功能,实现方法是将访问本地缓存的方法配置成动态类,相当于你自定义了这个方法进行 Mock,会在生产环境录制你配置的这个动态类方法的数据,回放相应的匹配出数据返回。
当然这种方式也存在不足之处:
- 缓存配置容易忽略,对回放通过率有很大影响;
- 每个应用都有自己的缓存实现,无法提前处理,需要人工参与,有配置成本。
AREX 其他优势
支持写接口测试
要验证系统修改后的业务正确性,仅校验返回结果是远远不够的,通常还需要验证中间过程数据的正确性,例如业务系统写数据库的数据内容是否正确等等。
针对这一点,AREX 在写接口测试也做了完美支持。
AREX 在录制和回放的过程中会记录下新旧版本系统对外的数据库请求,并将这两个请求进行比对,如果存在差异则会在回放报告中进行展示。
由于 AREX MOCK 了所有对第三方依赖的请求,支持数据库、消息队列、Redis 数据的验证,甚至支持验证运行时的内存数据,并且在回放的过程中不会真的产生对数据库的调用,因此不会产生脏数据。
生产问题快速定位
在实际使用过程中,AREX 还可以用来实现生产问题的快速定位。
生产问题出现后因版本差异、数据差异等问题,导致开发人员难以在本地复现,进行 Debug 的成本很高,很费事费力。
利用 AREX,可以强制在生产环境录制有问题的 Case(应答报文中会生成唯一的 Record ID),随后启动本地开发环境,发送请求的报文头添加此 Record ID,就可以在本地复原录制到的请求和数据,随后利用本地代码直接 Debug 生产问题。
AREX 自动化测试的实施与展望
AREX 在携程的推行效果
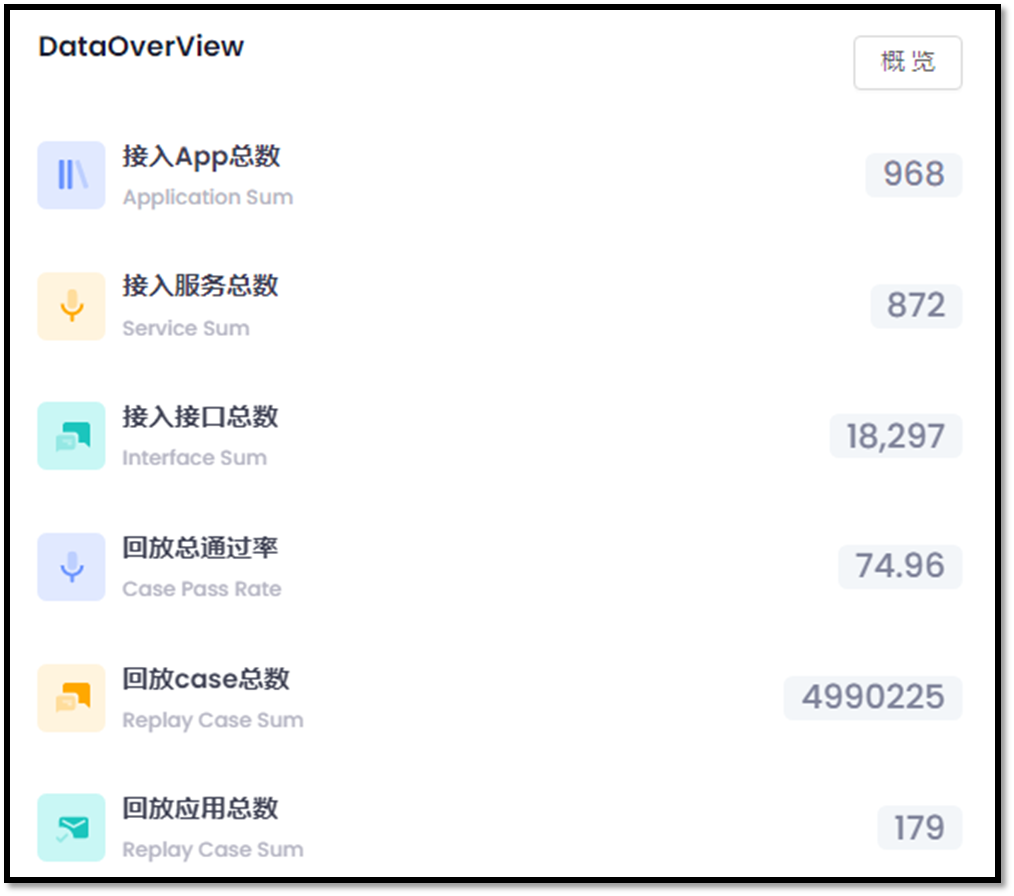
各 BU 在接入 AREX 后,除去前期需要一些熟悉工具、配置的学习成本外,明显减少了测试开发人员在自动化用例开发、数据 MOCK、构造数据方面的工作量,形成了良性循环,减少了漏测并增加了覆盖范围,有效提升了产品的质量。
其中在两个场景效果最显著:
- 技术重构项目,特别是请求应答不修改的场景。这种使用场景下,几乎不需要测试人员参与,开发人员自己就可以通过 AREX 进行快速自测,保证质量。
- 开发人员提升自测质量。
AREX 优化
初期 AREX 在携程内部试用阶段,大家对工具的评价还是很好的。但是,在扩大使用范围、特别是在有其他团队非主动接入时,就出现了各种问题:
- 误报率高(时间、uuid、序列号等等),前期比对过滤配置多。
- 代码变更的预期确认很麻烦,人工干预量大。
目前我们正在对 AREX 配置和比对能力进行重点优化。
配置增强
现阶段要保证高比对通过率需要大量的人工干预(比对忽略配置等),所以首先要做的就是降低用户配置成本:
- 可视化直观展示差异点
- 人工标记操作提升易用性
- 配置更新可重算和重新执行
同类聚合
通过聚合的方式将同类的错误进行多维度聚合,方便开发人员观察差异。最终达到大部分情况下,开发只要确认一个差异就可以去掉大部分的比对差异的效果。
算法降噪
- 预分析降噪
预分析降噪是将录制流量的生产版本发布到测试环境,对此版本进行回放并比对其差异,提前识别出类似于 token,序列号等的“噪声”点。
之后将噪声标记到规则库,作为知识库。
最后识别报文和数据的 Schema 变更,进行主动降噪,减少用户手工配置的成本。
- 比对知识库
比对是 AREX 的核心能力,但目前的比对是比较粗略的,误报率较高,我们希望可以做到在迭代测试中,增加比对知识的积累(非人工干预),形成比对知识库,帮助用户准确识别有效差异。例如将 Schema 的定义转成有效的比对规则。
精准测试
精准测试是为了缩小测试范围,后续 AREX 中也会引入精准测试,主要目的是做到明确比对差异的来源。
我们计划将代码变更、代码执行链路与 AREX 的回放关联起来,通过代码变更与差异结果的双向追溯,让用户“可观察”地确认问题。首先识别差异是否是由代码更新导致的预期中的差异,进一步主动过滤识别非预期问题的差异点。
经过对比对差异结果的优化处理,可以有效地降低研发配置成本、提升差异结果的精确度,这才是 AREX 的自动化回归测试真正可以落地的价值所在。
写在最后
AREX 经过不断的优化,逐步达到了用真实流量和数据进行回归测试的目标,降低了成本,提高了质量,达到了建设初期设定的目标。
当然还有很多需要优化和提升的地方,包括算法、性能、支持范围等等,需要进一步的优化发展。也希望各位有志之士可以加入到我们 AREX 开源项目的共建当中。