
本篇文章分享如何在 AWS 环境下快速搭建 AREX 服务,并使用 AWS 的 DocumentDB 作为数据库替换官方默认的 MongoDB,使用 ElastiCache 替换默认的 Redis。
AREX 是一款开源的基于流量录制回放技术的自动化回归测试平台,目前官方文档仅介绍了如何在本地及私有云部署,本篇文章分享如何 AWS 环境下快速搭建 AREX 服务,并使用 AWS 的 DocumentDB 作为数据库替换官方默认的 MongoDB,使用 ElastiCache 替换默认的 Redis。
安装 AREX
使用前需要注册 AWS 账号并对相应概念有一定了解,详细可参考 AWS 官方文档。
步骤一:准备一台 EC2 用于部署 AREX
操作系统选择 Amazon Linux 2 AMI。(Amazon Linux 2023 AMI 有部分应用安装不上,所以这里选择使用稳定的低版本操作系统)
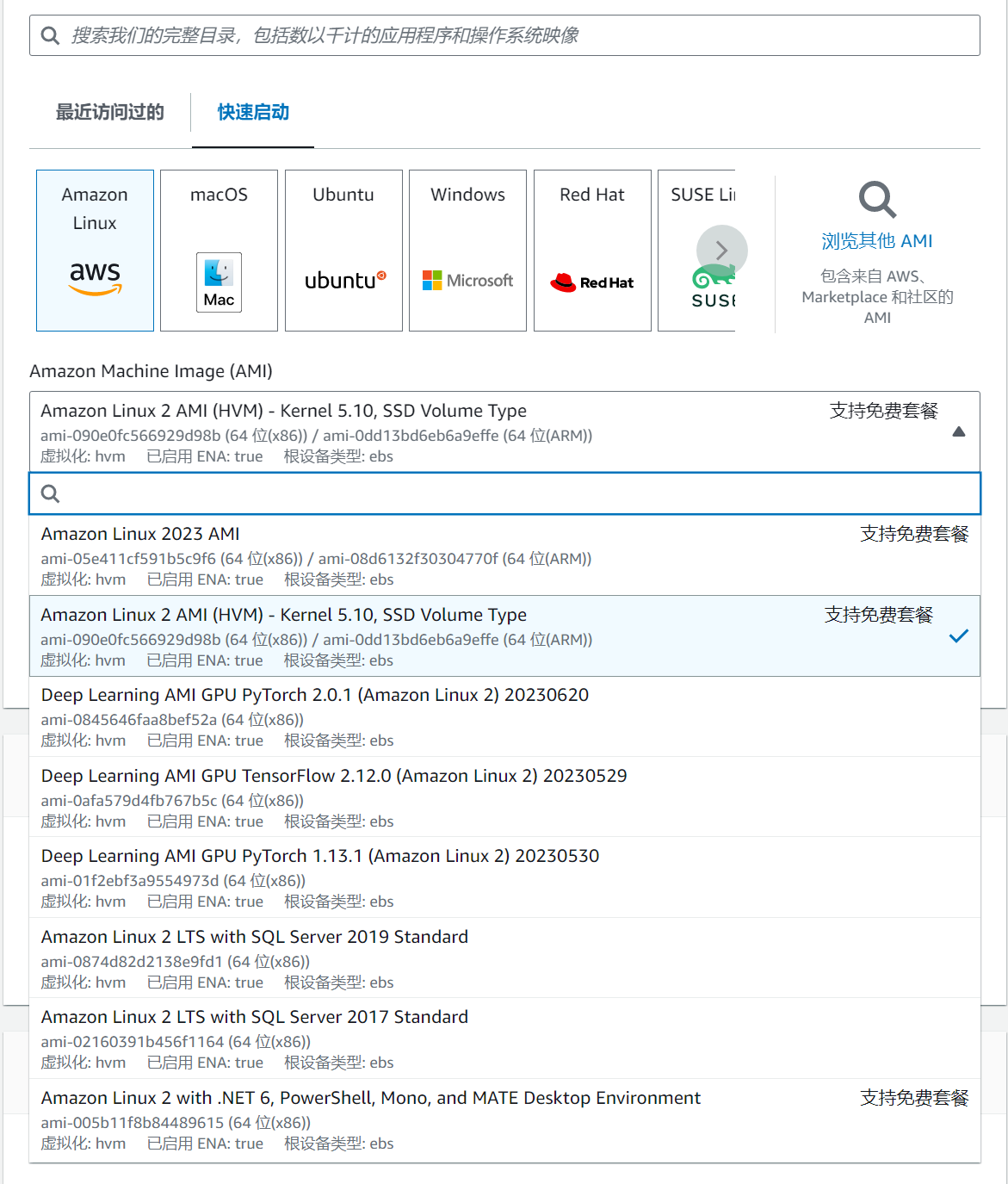
如果只是进行试用,建议最小配置选择 t3.large(2C8G)的机器。
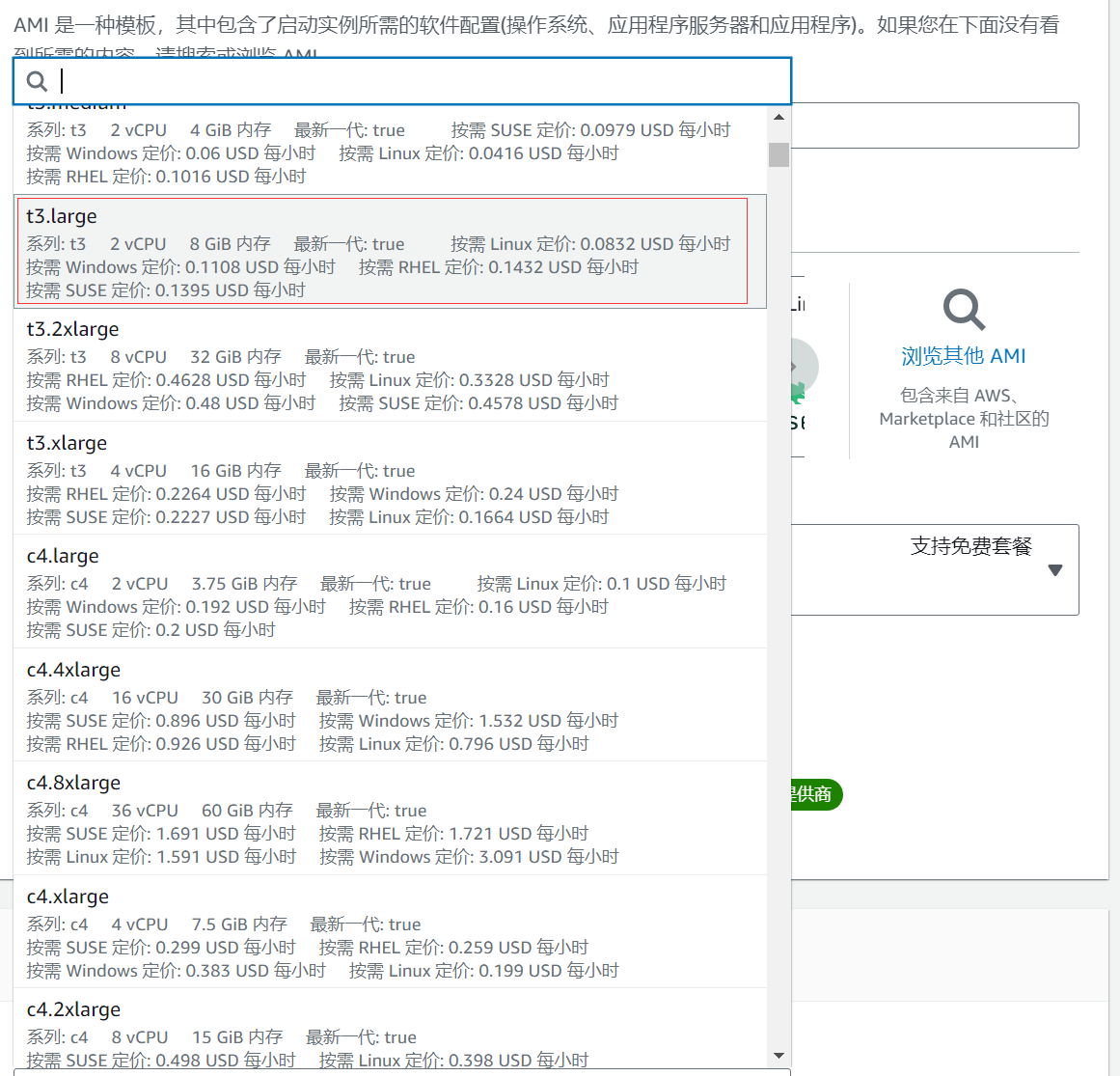
密钥对名称可以按照自己的需求创建并使用(方便快速链接到自己的 EC2)。后续创建 DocumentDB 的时候也可以共用该秘钥。
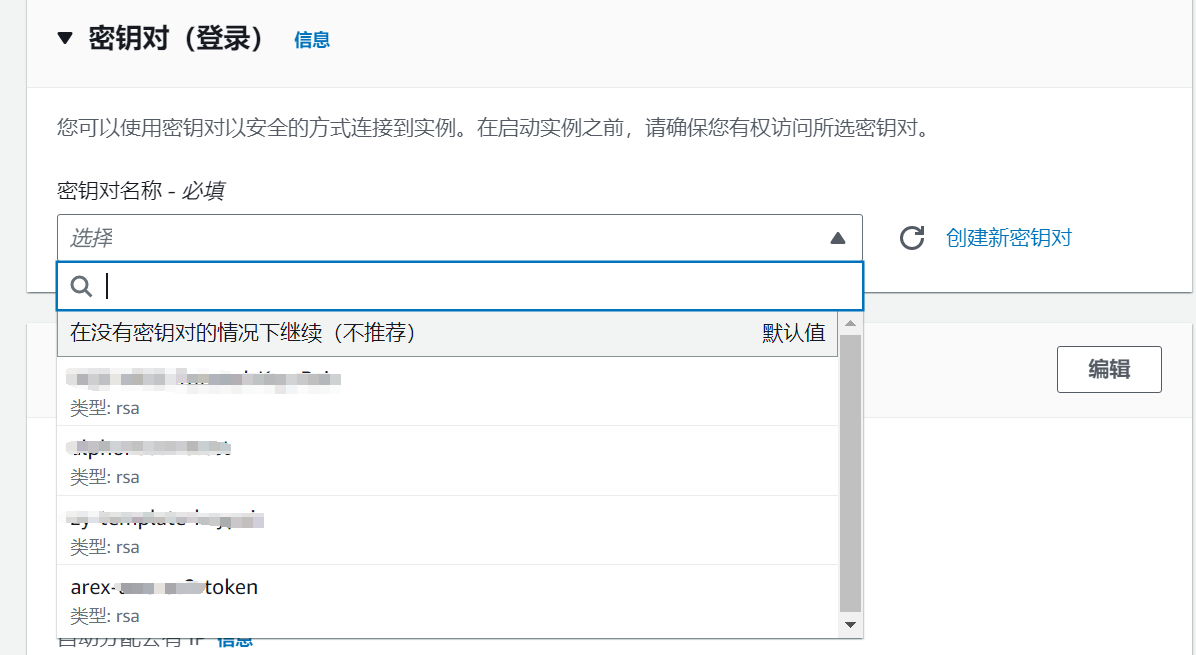
存储配置默认 8G 即可。
步骤二:创建 Amazon DocumentDB 集群
注意:在使用 DocumentDB 时,需要将其部署在与之关联的 EC2 实例所在的同一个虚拟私有云(VPC)中,保证它们之间能够进行通信。
创建 2 个 db.t3.medium 类型的实例,1 主 1 从两台机器,引擎版本选择 5.0.0。
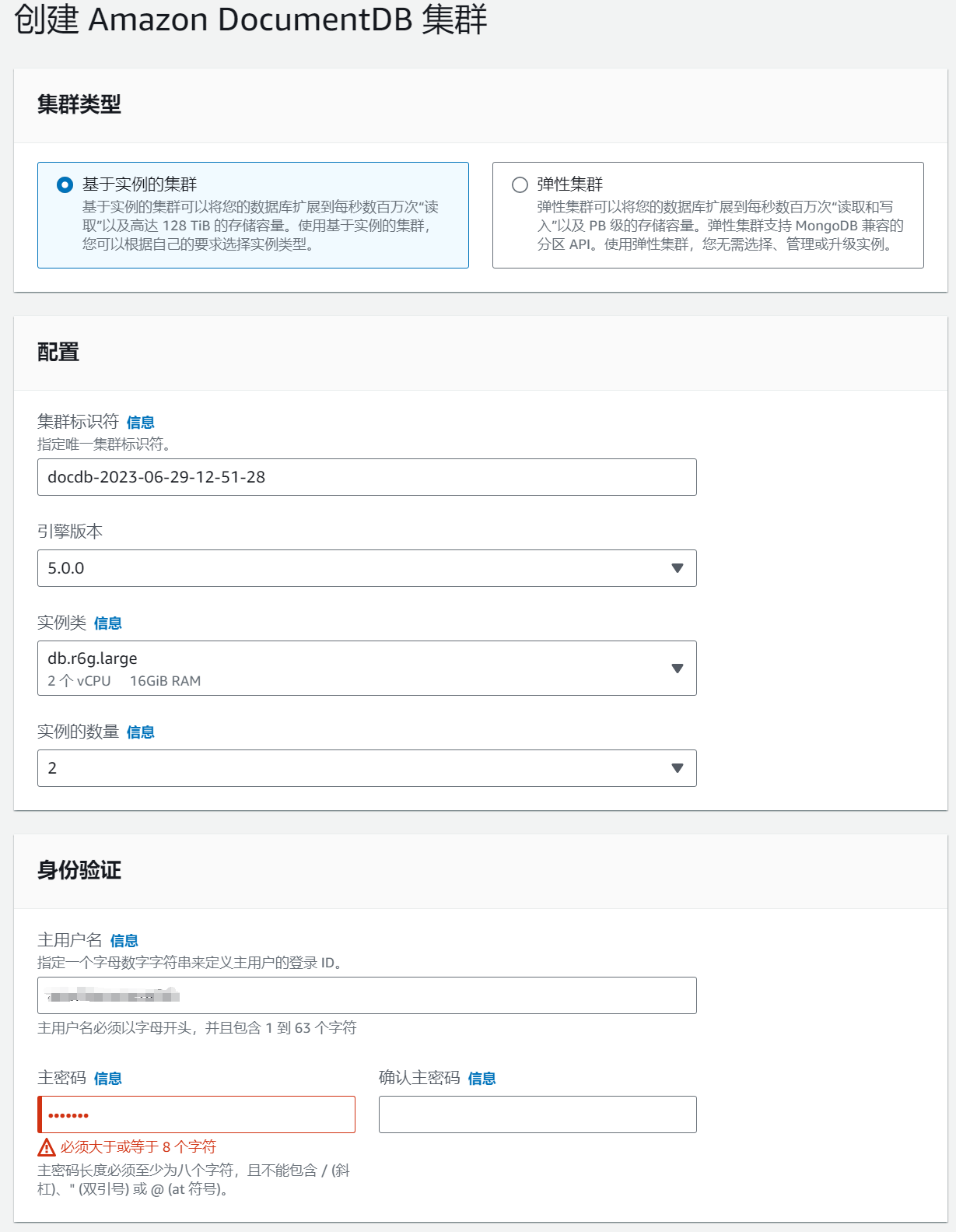
安装完成后,配置对应的入站规则以允许外部网络通过连接串进行访问。使用 mongo shell 验证连接串是否可用。
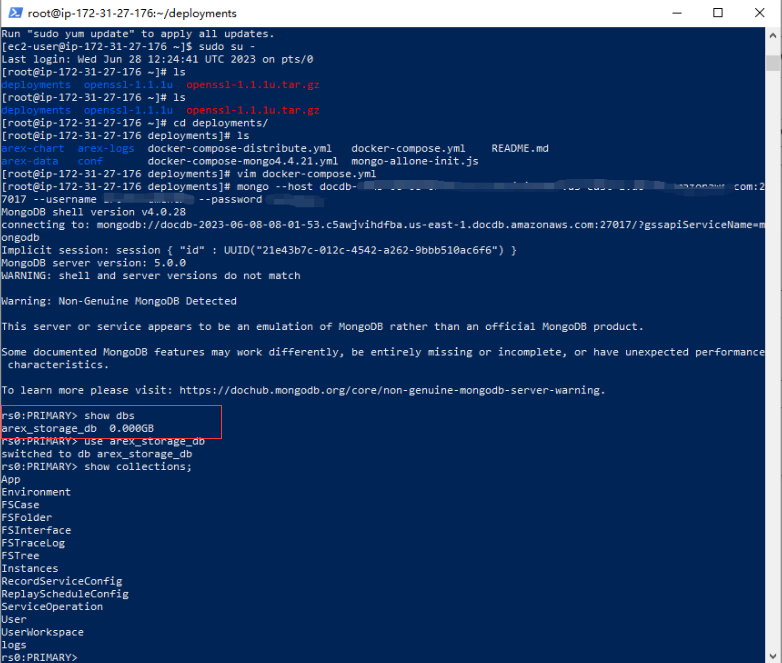
执行 show dbs 命令,出现上图中红框部分则表示 DocumentDB 创建成功。
步骤四:准备一台 ElastiCache 并创建 Redis 集群
在 AWS 控制台中搜索 ElastiCache 并创建 Redis 集群。注意:ElastiCache 必须与上述创建的 EC2 在同一个 VPC 中。
选择配置并创建新集群,试用阶段可以先禁用集群模式,正式使用时按需修改配置。
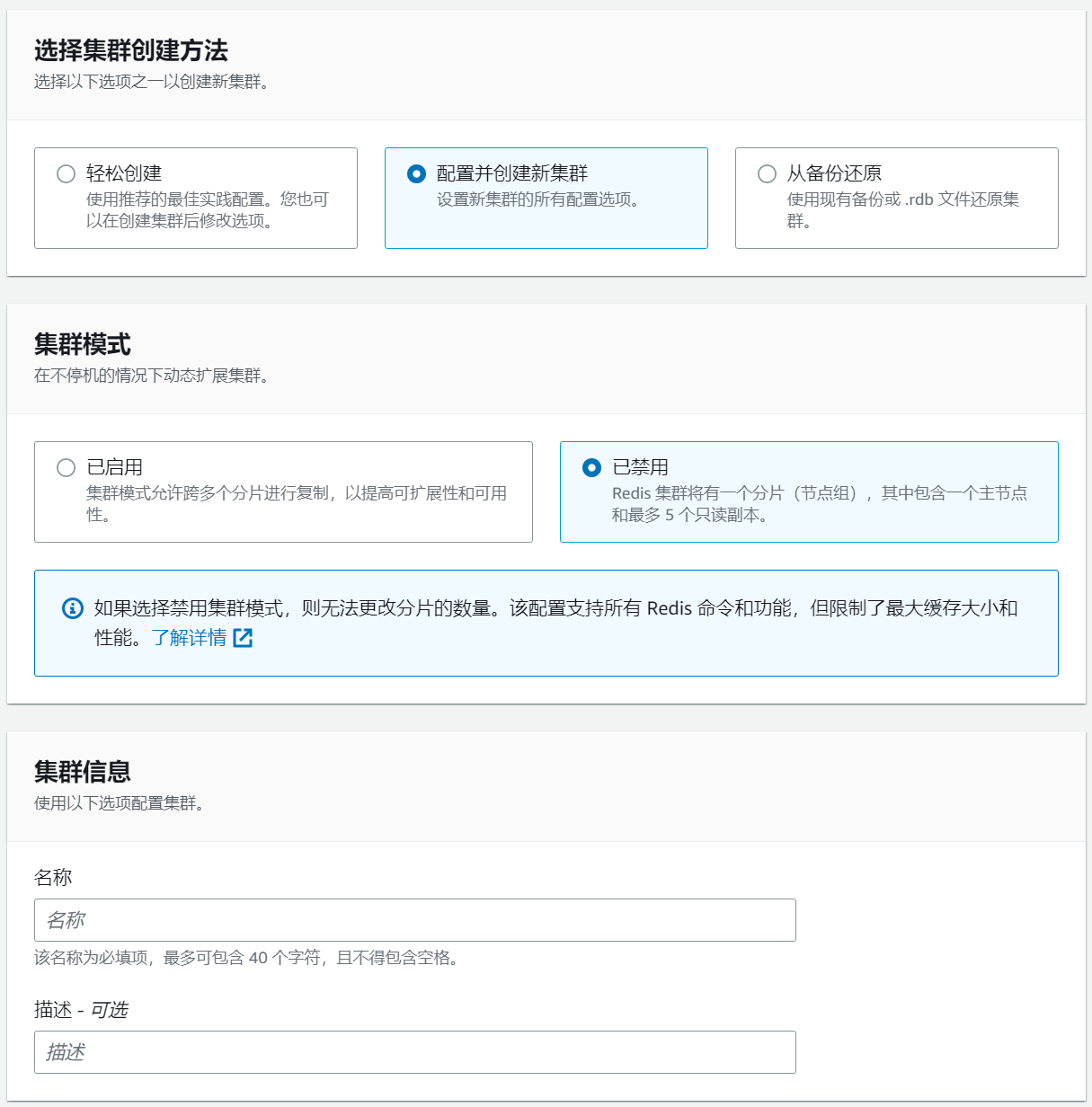
引擎版本选择 6.2,节点类型选择 cache.t3.micro,副本数量设置为 0。
选择创建新的子网组,选择和上述 EC2 同一个 VPC ID。
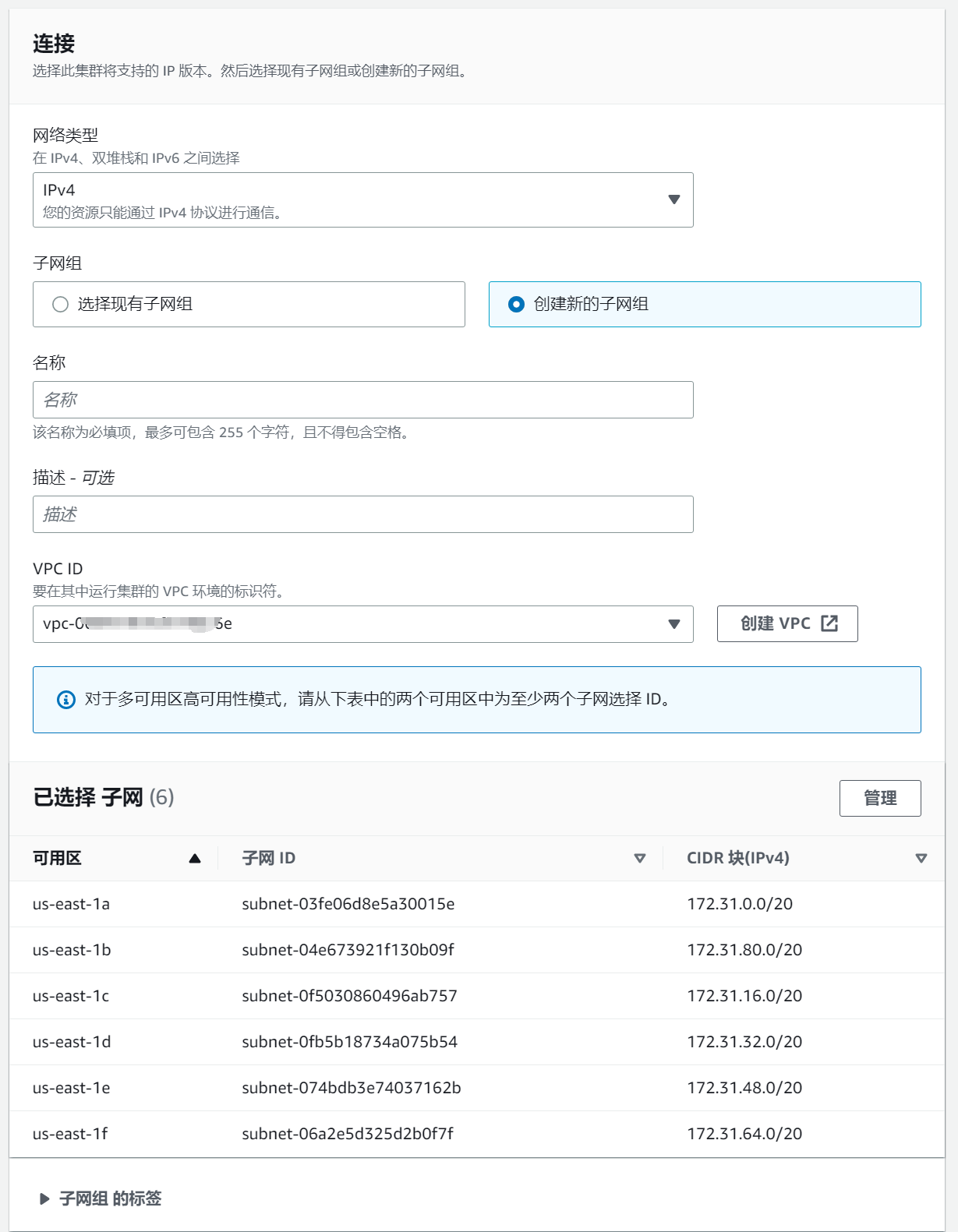
在 EC2 上通过 redis-cli 连接到 ElastiCache 检查是否连通。如果连接不上可以看下安全组对应的入站规则,根据自己网络情况进行配置即可。

步骤五:通过 docker-compose 安装 AREX
AREX 的安装非常简单,使用 Docker-Compose 命令,即可一键安装 AREX 所有基础服务组件。
这里简单介绍一下 AREX 的工作原理及各个服务组件。
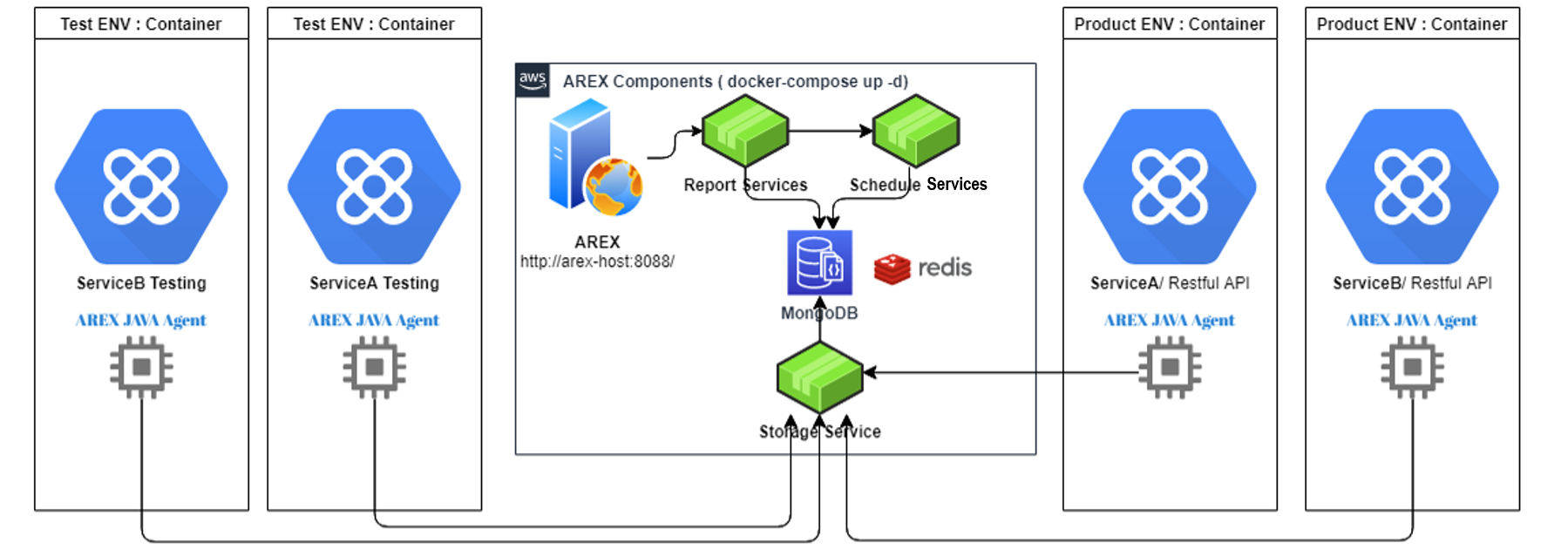
AREX 回归测试的工作原理是利用 AREX Java Agent 将生产环境中 Java 应用的数据流量和请求信息进行采样录制,并将这些信息发送给 AREX 数据存取服务(Storage Service),由数据存取服务导入数据库(mongoDB)中进行存储。当需要进行回放时,AREX 调度服务(Schedule Service)将会通过 Storage Service 从数据库中提取被测应用的录制数据,然后向目标验证服务发送接口请求。同时,Java Agent 会将录制的外部依赖的响应进行 Mock,代替真正的数据访问,传达给被测应用,目标服务处理完成请求逻辑后返回响应报文。随后调度服务会将录制的响应报文与回放的响应报文进行比对,验证系统逻辑正确性,并将比对结果推送给分析服务(Report Service),由其生成完整的回放测试报告,供测试人员分析录制回放差异。
首先,通过 git 命令克隆 AREX 仓库。
git clone --depth 1 https://github.com/arextest/deployments.git
cd deployments
配置 DocumentDB、ElastiCache
如要使用 AWS 的 DocumentDB 作为数据库替换官方默认的 MongoDB,并使用 ElastiCache 替换默认的 Redis,只需修改配置文件 docker-compose.yml 中的连接串,把文件中所有 MongoDB 的连接串都替换成 DocumentDB 的连接串,所有 Redis 的连接串都替换成 ElastiCache 的连接串即可。
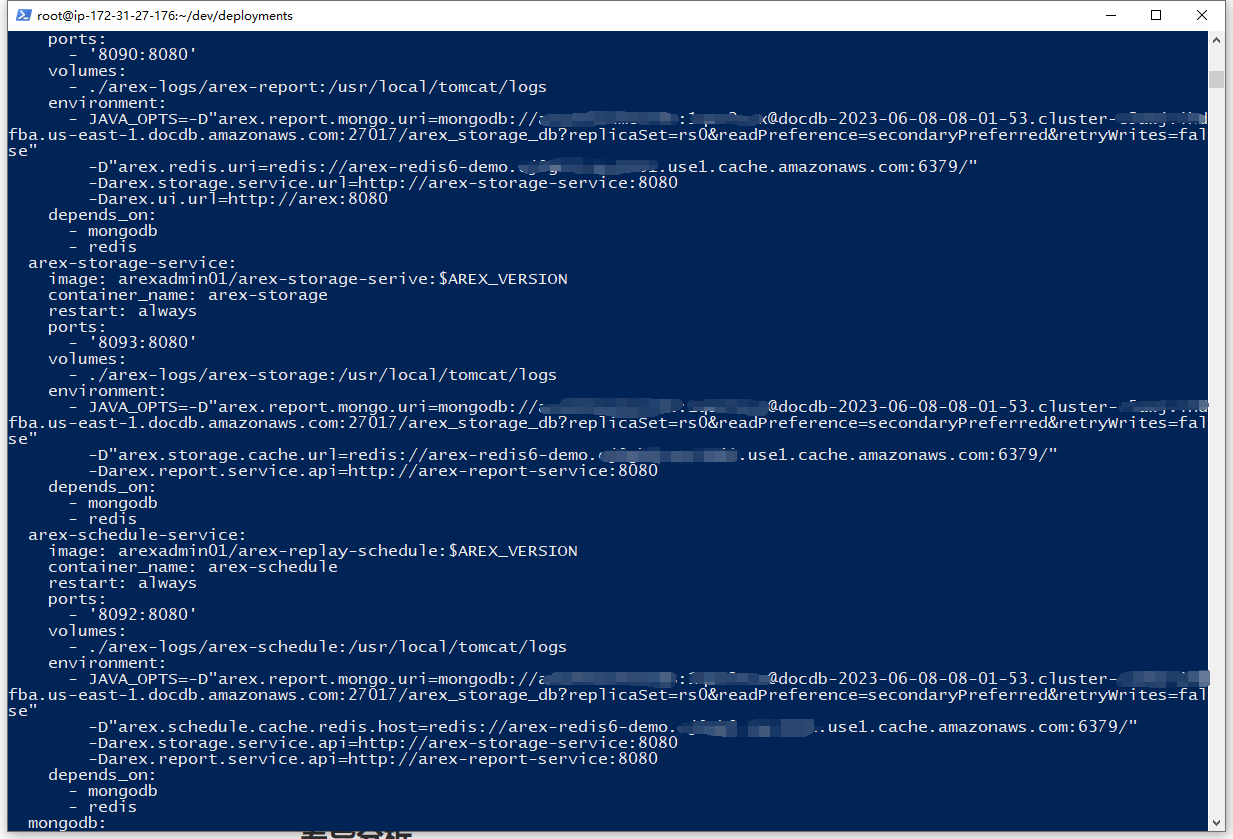
步骤六:启动 AREX
配置完成后,执行 docker-compose 一键启动 AREX 服务。
docker-compose up -d
服务启动后,在没有修改端口配置的情况下,直接访问 8088 端口进入 AREX 前端页面。
差异分析
在实际使用过程中,对于一个复杂的线上应用,业务场景复杂,录制及回放的用例数量巨大,如何分析差异点及排查问题成为难点。
为了减轻使用者分析差异时的工作量,AREX 对可能存在的大量差异点,使用聚合的方法进行了大幅度的简化。
差异场景聚合分析
首先是差异场景聚合,AREX 对差异场景相同的多个用例进行了聚合展示。在介绍差异场景聚合逻辑之前,先大概了解一下 AREX 中用例(Case)的基本概念。
AREX 用例概念
在 AREX 中,一个用例通常由多个步骤组成,每个步骤包含了一个请求和一个响应。请求可以是主入口,也可以是外部调用(包括 DB、Redis 等)。在每个步骤中,都会记录请求的参数和响应结果等信息,用于后续的对比。如果录制与回放时的主入口响应,以及外部依赖的请求均无差异,则视为该用例回放通过。
这里的主入口和外部调用我们称之为 Mock 的类型。
Mock 的差异类型
每个 Mock 类型的对比差异类型会被分为三种情况:
- new call:这种差异类型表示该主入口或外部调用的 Mock 在录制时不存在,但在回放时存在,即新增了调用,通常是因为有新功能的迭代。
- call missing:表示在录制时存在,但在回放时缺失了调用,通常是因为项目进行了优化,移除了某些不必要的调用关系。
- value diff:表示在录制和回放时都存在,但在对比过程中某些节点有差异。后续章节中会具体介绍如何分析这些差异。
差异场景聚合
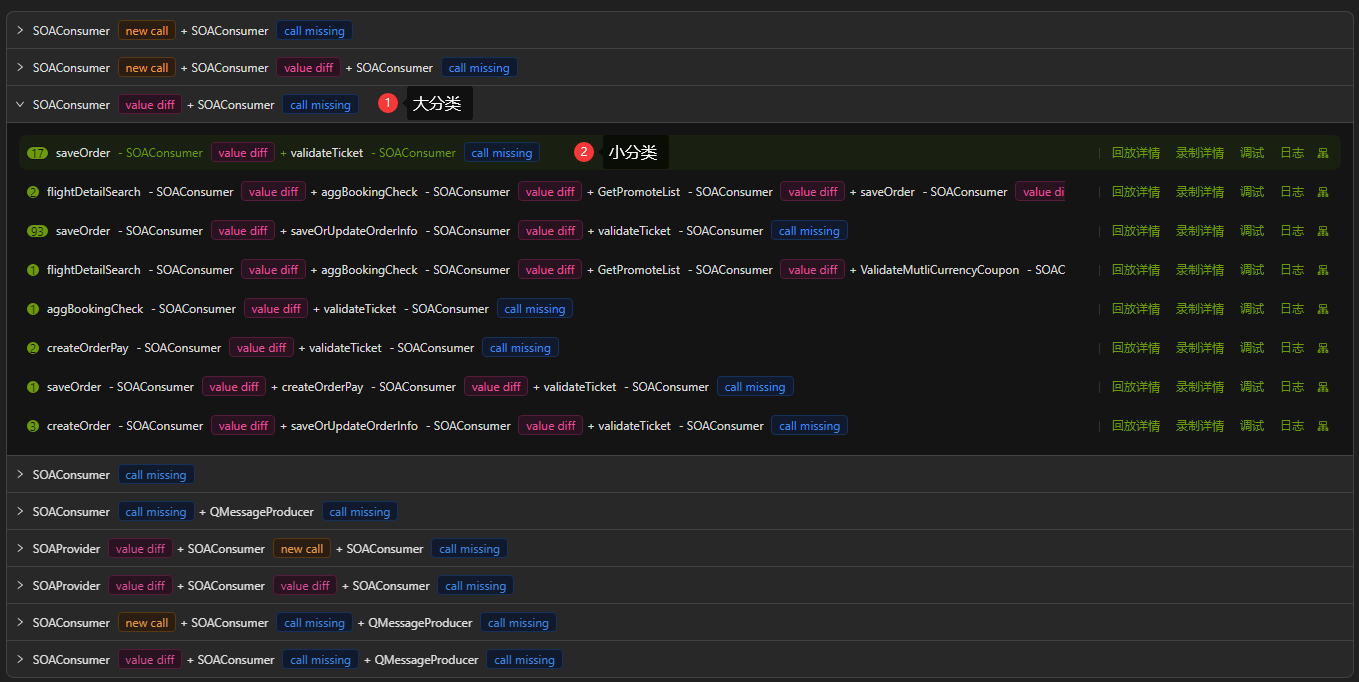
在进行流量回放测试时,针对可能出现的用例数量较大的情况,AREX 会通过一些聚合的操作,将相似的用例进行合并,以减少差异点的数量,便于用户对数据进行分析。如下图所示,聚合相似差异场景后,每个差异场景下仅选取一条用例作为展示。
场景聚合逻辑
有了上述 Mock 差异类型的概念,接下来介绍下差异用例场景聚合的逻辑。差异用例场景聚合是为了将具有相同 Mock 类型和差异类型的用例聚合在一起形成一个场景,从而帮助用户更快速地了解整个场景中的用例情况,减少用户需要分析的用例数量,提高分析用例的效率。
首先,根据 Mock 的 type 类型和差异类型的组合,AREX 会生成一个唯一的键,将所有用例分类聚合到这些键中,形成一个大分类。如上图中标注的 ①大分类。
其次,每个大分类中的用例都会再根据具体的 Mock 和差异类型的排列生成一个子唯一键,进一步对用例进行分类。这样做的目的是为了更加细致地分类,以便更快速地分析差异用例,具体可见上图中 ②小分类 的示例。每个小分类中有多少个用例数量会标记在该分类的最前面。
差异点分析
其次在每个差异场景中,AREX 对相似的差异节点也进行了聚合展示。
差异点聚合逻辑
在某些大报文的场景下,有些大数组中的差异点会非常多,一方面不利于前端展示,另一方面增加了使用者分析差异点的复杂度。
为了解决这个问题,AREX 将差异点按照模糊路径进行聚合。这里的模糊路径指的是不带数组下标的 JSON 节点路径。例如,一个 JSON 对象中有一个名为 “items” 的数组,数组中有多个元素 “items[0]”、“items[1]”、“items[2]” 等。在模糊路径中,这些路径会被合并为 “items”,从而实现聚合。
新增节点
在比较两个 JSON 对象时,如果发现某一边 JSON 对象中存在一个节点,但是另一边的对象中不存在该节点,那么我们就认为该节点是“新增节点”,如下图中,仅出现在右侧对象中的 cardpayfee 节点。同时为了方便用户查看,AREX 会将新增节点的所有祖先节点都标注为褐色,以突出显示该节点的位置。这样,用户可以清晰地看到该节点在另一侧对象中的位置,从而更好地分析问题。
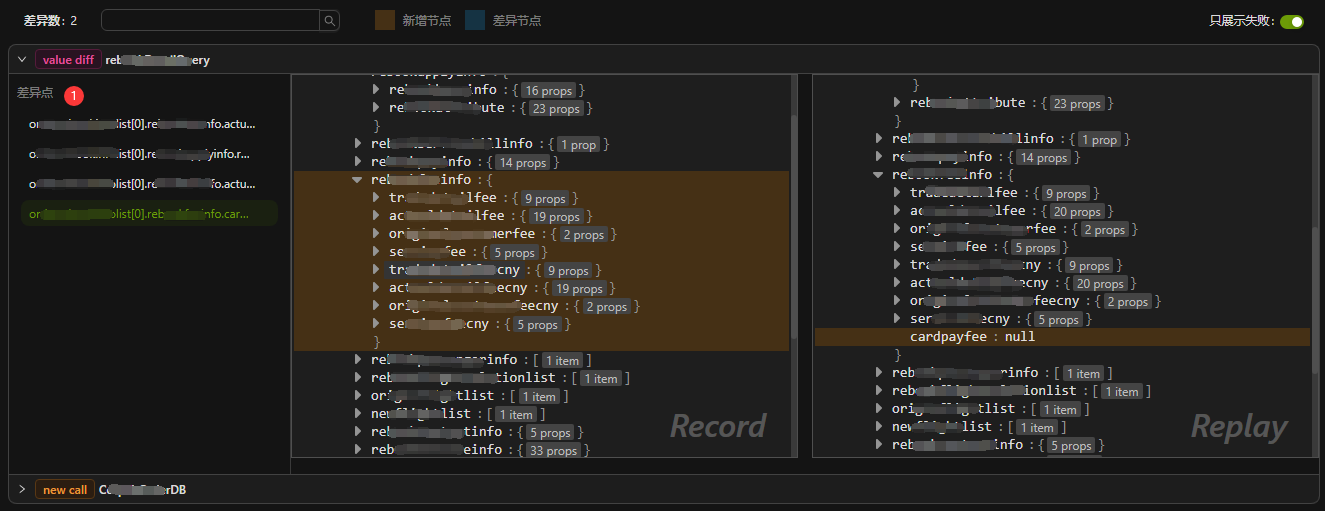
差异节点
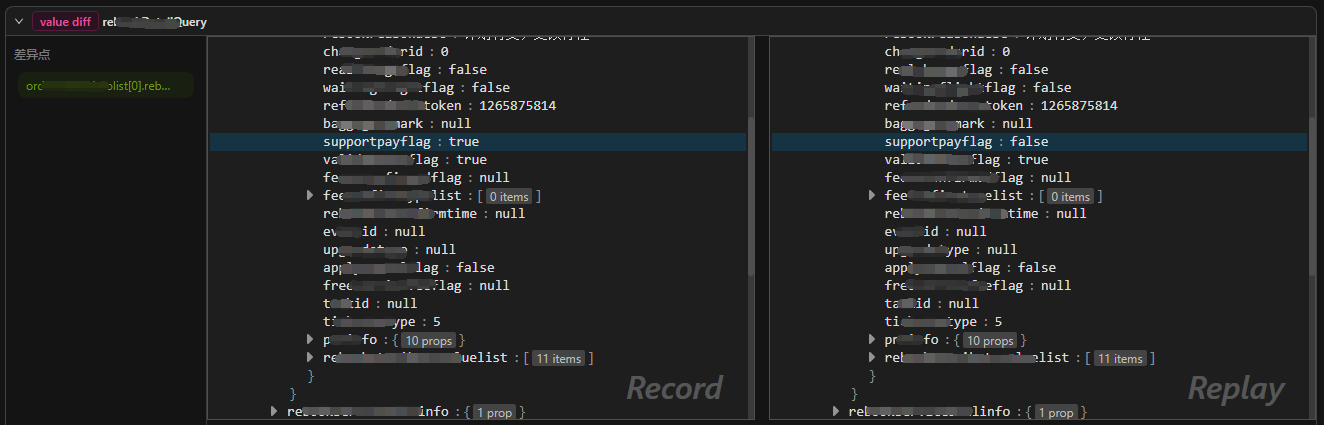
如果左右两边对象都存在某节点,但节点的值不一致,就可以认为该节点是“差异节点”,AREX 会使用蓝色背景高亮显示这些节点。不同于新增节点,这种类型的差异点只会出现在叶子节点上,因为只有叶子节点才有具体的值可以进行比较。